
Por trás do menor e mais poderoso GPT-4o mini, o futuro dos modelos de IA não é mais tão grande quanto melhor
Na semana passada, a OpenAI assumiu a liderança ao lançar um grande movimento tarde da noite. O mini GPT-4o lançado deu um bom show de “derrotar o grande com o pequeno”, levando o GPT-3.5 Turbo à “aposentadoria” e até superando. na grande arena de modelos LMSYS passou no GPT-4.
Quanto ao modelo grande Llama 3.1 lançado pela Meta esta semana, se o tamanho 405B do primeiro escalão ainda for esperado, então as versões de tamanho 8B e 70B que realizam “pequenas vitórias sobre grandes” trazem mais surpresas.
E este pode não ser o fim da competição de modelos pequenos, mas provavelmente um novo ponto de partida.

Não é que os modelos grandes sejam inacessíveis, mas os modelos pequenos são mais económicos
No vasto mundo dos círculos de IA, os pequenos modelos sempre tiveram suas próprias lendas.
Olhando para fora, o sucesso de bilheteria do ano passado, Mistral 7B, foi aclamado como o "melhor modelo 7B" assim que foi lançado. Ele superou o modelo de parâmetro 13B Llama 2 em vários benchmarks de avaliação e o superou em raciocínio, matemática e geração de código. .
Este ano, a Microsoft também abriu o código-fonte do modelo grande de parâmetros pequenos mais poderoso phi-3-mini. Embora o número de parâmetros seja de apenas 3,8B, os resultados da avaliação de desempenho excedem em muito o nível da mesma escala de parâmetros e são comparáveis a modelos maiores, como. Soneto GPT-3.5 e Claude-3.
Olhando para dentro, a Wall Intelligence lançou o MiniCPM, um modelo de linguagem lado a lado com apenas parâmetros de 2B. Ele usa um tamanho menor para obter um desempenho mais forte. Seu desempenho supera o popular modelo francês Mistral-7B, conhecido como ". Pequeno Aço". arma".

Não muito tempo atrás, o MiniCPM-Llama3-V2.5, que possui apenas 8B de tamanho de parâmetro, superou modelos maiores como GPT-4V e Gemini Pro em termos de desempenho abrangente multimodal e recursos de OCR. Equipe universitária de IA.
Até a semana passada, a OpenAI, que bombardeava tarde da noite, lançou o que descreveu como "o modelo de pequeno parâmetro mais poderoso e econômico" – GPT-4o mini, que trouxe a atenção de todos de volta ao modelo pequeno.
Desde que a OpenAI arrastou o mundo para a imaginação da IA generativa, desde contextos longos, até parâmetros rolantes, até agentes, e agora até guerras de preços, o desenvolvimento interno e externo sempre girou em torno de uma lógica – permanecer no campo avançando em direção à comercialização . Na mesa de cartas.
Portanto, no campo da opinião pública, o que mais chama a atenção é que a OpenAI, que reduziu os preços, parece estar entrando em uma guerra de preços.
Muitas pessoas podem não ter uma ideia clara do preço do GPT-4o mini. O GPT-4o mini custa 15 centavos por 1 milhão de tokens de entrada e 60 centavos por 1 milhão de tokens de saída, o que é mais de 60% mais barato que o GPT-3.5 Turbo.
Em outras palavras, o GPT-4o mini gera um livro de 2.500 páginas por apenas 60 centavos.

O CEO da OpenAI, Sam Altman, também lamentou no X que, comparado ao GPT-4o mini, o modelo mais poderoso de dois anos atrás, não apenas apresentava uma enorme lacuna de desempenho, mas também tinha um custo de uso 100 vezes maior do que agora.
Embora a guerra de preços para modelos grandes esteja se tornando cada vez mais acirrada, alguns modelos pequenos de código aberto, eficientes e econômicos, têm maior probabilidade de atrair a atenção do mercado. Afinal, não é que modelos grandes não possam ser usados, mas que modelos pequenos sejam mais econômicos. .
Por um lado, quando as GPUs em todo o mundo estão esgotadas ou mesmo esgotadas, pequenos modelos de código aberto com custos mais baixos de treinamento e implantação são suficientes para ganhar gradualmente vantagem.
Por exemplo, o MiniCPM lançado pela Mianbi Intelligence pode atingir uma queda abrupta nos custos de inferência com seus parâmetros menores e pode até mesmo obter inferência de CPU. Requer apenas uma máquina para treinamento contínuo de parâmetros e uma placa gráfica para ajuste fino de parâmetros. também são melhorias contínuas de espaço de custo.
Se você é um desenvolvedor maduro, pode até treinar um modelo vertical na área jurídica construindo você mesmo um modelo pequeno, e o custo de inferência pode ser apenas um milésimo do ajuste fino de um modelo grande.

A implementação de algumas aplicações de "modelos pequenos" no lado do terminal permitiu que muitos fabricantes vissem o início da lucratividade. Por exemplo, a Facewall Intelligence ajudou o Tribunal Popular Intermediário de Shenzhen a lançar um sistema de julgamento assistido por inteligência artificial, provando o valor da tecnologia para o mercado.
É claro que é mais correto dizer que a mudança que começaremos a ver não é uma mudança de modelos grandes para modelos pequenos, mas uma mudança de uma categoria única de modelos para um portfólio de modelos, dependendo a escolha do modelo certo. nas necessidades específicas da organização, Complexidade das tarefas e recursos disponíveis.
Os modelos pequenos, por outro lado, são mais fáceis de implementar e integrar em dispositivos móveis, sistemas embarcados ou ambientes de baixo consumo de energia.
A escala de parâmetros de um modelo pequeno é relativamente pequena Em comparação com um modelo grande, sua demanda por recursos de computação (como poder de computação de IA, memória, etc.) é menor e pode funcionar mais suavemente em dispositivos finais com limitações. recursos. Além disso, os equipamentos finais geralmente têm requisitos mais extremos em termos de consumo de energia, geração de calor e outros problemas. Modelos pequenos especialmente projetados podem se adaptar melhor às limitações dos equipamentos finais.

O CEO da Honor, Zhao Ming, disse que, devido a problemas de poder de computação de IA no lado do cliente, os parâmetros podem estar entre 1B e 10B. A capacidade de computação em nuvem de grandes modelos de rede pode atingir 10-100 bilhões ou até mais. os dois. .
O telefone fica em um espaço bem limitado, certo? Ele suporta 7 bilhões em uma bateria limitada, dissipação de calor limitada e ambiente de armazenamento limitado. Se você imagina que há tantas restrições, deve ser o mais difícil.
Também revelamos os heróis dos bastidores responsáveis pela operação dos smartphones da Apple. Entre eles, o modelo pequeno 3B ajustado é dedicado a tarefas como resumo e polimento. Com a bênção de um adaptador, suas capacidades são melhores do que. Gemma-7B e é adequado para execução em terminais móveis. Incluindo o Google também planeja atualizar a versão 2B do pequeno modelo Gemma-2 adequado para terminais de telefonia móvel nos próximos meses.

Recentemente, o ex-guru da OpenAI Andrej Karpathy também julgou que a competição no tamanho do modelo será uma "involução reversa", não ficando cada vez maior, mas quem é menor e mais flexível.
Por que os modelos pequenos podem derrotar os grandes com os pequenos?
A previsão de Andrej Karpathy não é infundada.
Nesta era centrada em dados, os modelos estão se tornando cada vez maiores e mais complexos. A maioria dos modelos muito grandes (como o GPT-4) treinados em dados massivos são, na verdade, usados para lembrar um grande número de detalhes irrelevantes, ou seja, memorizar informações. Pela rota.
No entanto, o modelo ajustado pode até “ganhar o grande com o pequeno” em tarefas específicas, e sua usabilidade é comparável a muitos “modelos supergrandes”.
O CEO da Hugging Face, Clem Delangue, também sugeriu que até 99% dos casos de uso podem ser resolvidos usando modelos pequenos e previu que 2024 será o ano dos modelos de linguagem pequena.
Antes de investigar as razões, devemos primeiro popularizar alguns conhecimentos científicos.
Em 2020, a OpenAI propôs em um artigo uma lei famosa: Lei de escala, o que significa que à medida que o tamanho do modelo aumenta, seu desempenho também aumentará. Com a introdução de modelos como o GPT-4, as vantagens da lei de escala surgiram gradualmente.
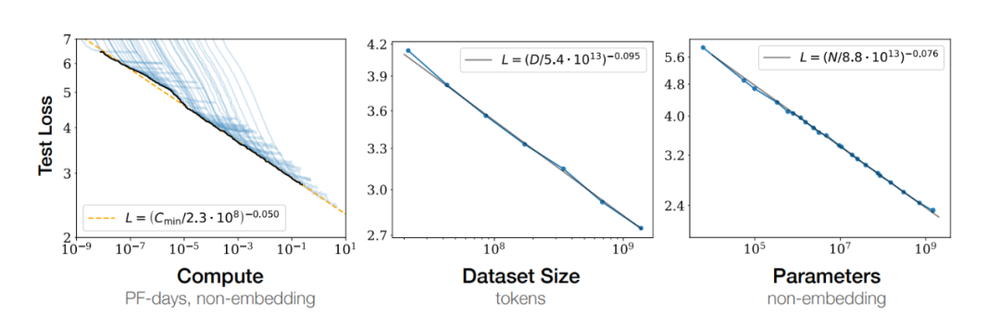
Pesquisadores e engenheiros na área de IA acreditam firmemente que, ao aumentar o número de parâmetros do modelo, a capacidade de aprendizagem e a capacidade de generalização do modelo podem ser melhoradas ainda mais. Dessa forma, testemunhamos a escala do modelo saltar de bilhões de parâmetros para centenas de bilhões, e até subir para modelos com trilhões de parâmetros.
No mundo da IA, o tamanho de um modelo não é o único critério para medir a sua inteligência.
Pelo contrário, um modelo pequeno bem concebido, ao optimizar o algoritmo, melhorar a qualidade dos dados e adoptar tecnologia de compressão avançada, pode muitas vezes mostrar um desempenho comparável ou até melhor do que o de um modelo grande em tarefas específicas. Esta estratégia de usar o pequeno para obter maiores resultados está se tornando uma nova tendência no campo da IA.
Melhorar a qualidade dos dados é uma das maneiras de os modelos pequenos vencerem os grandes.
Satish Jayanthi, CTO e cofundador da Coalesce, descreveu certa vez o papel dos dados nos modelos:
Se o LLM existisse no século XVII, e perguntássemos ao ChatGPT se a Terra era redonda ou plana, e ele respondesse que a Terra era plana, seria porque os dados que fornecemos o convenceram de que isso era verdade. Os dados que fornecemos ao LLM e como o treinamos afetarão diretamente seu resultado.
Para produzir resultados de alta qualidade, grandes modelos de linguagem precisam ser treinados em dados direcionados de alta qualidade para tópicos e domínios específicos. Assim como os alunos precisam de livros didáticos de qualidade para aprender, os LLMs também precisam de fontes de dados de qualidade.

Abandonando a tradicional estética violenta de trabalhar duro para alcançar milagres, Liu Zhiyuan, professor associado permanente do Departamento de Ciência da Computação da Universidade de Tsinghua e cientista-chefe da inteligência voltada para a parede, propôs recentemente a lei voltada para a parede na era das grandes modelos, ou seja, a densidade de conhecimento do modelo continua a aumentar, duplicando em média a cada oito meses.
Entre eles, densidade de conhecimento = capacidade do modelo/parâmetros do modelo envolvidos no cálculo.
Liu Zhiyuan explicou vividamente que se você receber 100 perguntas do teste de QI, sua pontuação não dependerá apenas de quantas perguntas você responder corretamente, mas também do número de neurônios que você usa para responder a essas perguntas. Quanto mais tarefas você realizar com menos neurônios, maior será o seu QI.
Esta é exatamente a ideia central que a densidade do conhecimento transmite:
Tem dois elementos. Um elemento é a capacidade deste modelo. O segundo elemento é o número de neurônios necessários para esta capacidade, ou o correspondente consumo de energia computacional.
Comparado com os 175 bilhões de parâmetros GPT-3 lançados pela OpenAI em 2020, em 2024 ela lançou o MiniCPM-2.4B com o mesmo desempenho, mas apenas 2,4 bilhões de parâmetros do GPT-3, o que aumentou a densidade de conhecimento em cerca de 86 vezes.
Um estudo da Universidade de Toronto também mostra que nem todos os dados são necessários, identificando subconjuntos de alta qualidade a partir de grandes conjuntos de dados que são mais fáceis de processar e retêm toda a informação e diversidade no conjunto de dados original.
Mesmo que até 95% dos dados de treino sejam removidos, o desempenho preditivo do modelo dentro de uma distribuição específica pode não ser significativamente afetado.

O exemplo mais recente é o modelo grande Meta Llama 3.1.
Quando o Meta treinou o Llama 3, ele alimentou dados de treinamento de tokens de 15T, mas Thomas Scialom, um pesquisador do Meta AI responsável pelo trabalho pós-treinamento do Llama2 e do Llama3, disse: O texto na Internet está cheio de informações inúteis e treinamento baseado em esta informação é um desperdício de recursos computacionais.
"Não há respostas escritas manualmente no treinamento posterior do Llama 3… ele apenas usa dados puramente sintéticos do Llama 2."
Além disso, a destilação do conhecimento também é um dos métodos importantes de “conquistar o grande com o pequeno”.
A destilação de conhecimento refere-se ao uso de um "modelo de professor" grande e complexo para orientar o treinamento de um "modelo de aluno" pequeno e simples, que pode transferir o desempenho poderoso e a capacidade de generalização superior do modelo grande para modelos computacionais mais leves e menores que custam menos.

Após o lançamento do Llama 3.1, o CEO da Meta, Zuckerberg, escreveu um longo artigo "Open Source AI Is the Path Forward", no qual também destacou a importância de ajustar e destilar pequenos modelos.
Precisamos treinar, aperfeiçoar e refinar nossos próprios modelos. Cada organização tem necessidades diferentes que são melhor atendidas com o uso de modelos treinados ou ajustados em diferentes escalas e com dados específicos.
As tarefas no dispositivo e as tarefas de classificação requerem modelos pequenos, enquanto tarefas mais complexas requerem modelos grandes.
Agora você pode pegar modelos Llama de última geração, continuar a treiná-los com seus próprios dados e, em seguida, destilá-los até o tamanho de modelo que melhor atenda às suas necessidades – sem que nós ou qualquer outra pessoa vejamos seus dados.
Também se acredita geralmente na indústria que as versões 8B e 70B do Meta Llama 3.1 são destiladas em copos ultragrandes. Portanto, o desempenho geral foi significativamente melhorado e a eficiência do modelo também é maior.
Ou a otimização da arquitetura do modelo também é fundamental. Por exemplo, a intenção original do design do MobileNet é implementar modelos eficientes de aprendizagem profunda em dispositivos móveis.
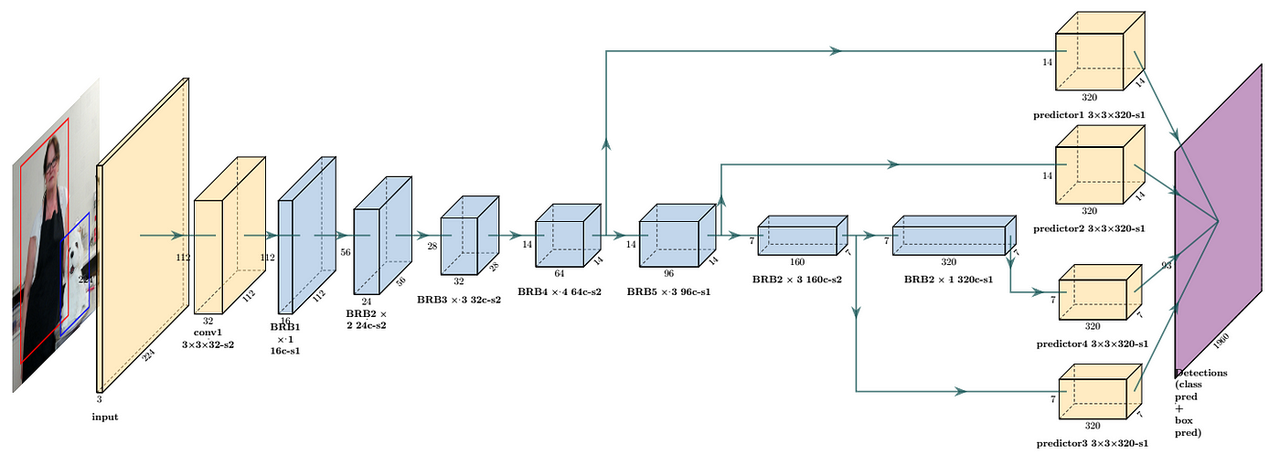
Reduz significativamente o número de parâmetros do modelo por meio de convolução separável em profundidade. Comparado ao ResNet, o MobileNetV1 reduz o número de parâmetros em cerca de 8 a 9 vezes.
MobileNet é computacionalmente mais eficiente devido ao número reduzido de parâmetros. Isto é especialmente importante para ambientes com recursos limitados, como dispositivos móveis, pois pode reduzir significativamente os requisitos de computação e armazenamento sem sacrificar muito o desempenho.
Apesar dos progressos realizados a nível técnico, a própria indústria da IA ainda enfrenta o desafio do investimento a longo prazo e dos custos elevados, e o ciclo de retorno é relativamente longo.
De acordo com estatísticas incompletas do "Daily Economic News", no final de abril deste ano, um total de cerca de 305 modelos grandes foram lançados na China, mas em 16 de maio, ainda havia cerca de 165 modelos grandes que ainda não haviam sido lançados. registro concluído.
O fundador do Baidu, Robin Li, criticou publicamente que a existência de muitos modelos básicos atuais é um desperdício de recursos e sugeriu que os recursos deveriam ser mais usados para explorar a possibilidade de combinar modelos com indústrias e desenvolver a próxima superaplicação potencial.

Esta é também uma questão central na actual indústria da IA, a contradição desproporcional entre o aumento do número de modelos e a implementação de aplicações práticas.
Perante este desafio, o foco da indústria voltou-se gradualmente para a aceleração da aplicação da tecnologia de IA, e pequenos modelos com baixos custos de implementação e maior eficiência tornaram-se um ponto de avanço mais adequado.
Então percebemos que começaram a surgir alguns modelos pequenos com foco em áreas específicas, como modelos grandes para culinária e modelos grandes para transmissão ao vivo. Embora esses nomes possam parecer um pouco blefantes, eles estão exatamente no caminho certo.
Em suma, a IA no futuro não será mais uma existência única e enorme, mas será mais diversificada e personalizada. A ascensão dos modelos pequenos é um reflexo desta tendência. Seu excelente desempenho em tarefas específicas prova que “pequeno, mas bonito” também pode conquistar respeito e reconhecimento.
Mais uma coisa
Se você quiser executar o modelo antecipadamente no seu iPhone, você também pode tentar um aplicativo iOS chamado “Hugging Chat” lançado pela Hugging Face.
O aplicativo pode ser baixado com a ajuda da conta da Magic Hemei District App Store e os usuários podem acessar e usar vários modelos de código aberto incluindo, mas não se limitando a Phi 3,
Mixtral, Command R+ e outros modelos.
Lembrete caloroso, para melhor experiência e desempenho, é recomendável usar a versão Pro de última geração do iPhone.
Link para download: https://apps.apple.com/us/app/huggingchat/id6476778843
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
