
O grande modelo de código aberto mais poderoso explode tarde da noite! Llama 3 Return of the King, quase tão bom quanto GPT-4, Musk gosta Link de experiência em anexo |
Sem muitas surpresas, a Meta chegou a “explodir as ruas” com a série de modelos Llama 3, que são conhecidos como “os grandes modelos de código aberto mais poderosos da história”.
Especificamente, a Meta abriu o código-fonte de dois modelos de tamanhos diferentes, 8B e 70B.
- Llama 3 8B: Basicamente tão poderoso quanto o maior Llama 2 70B.
- Llama 3 70B: O modelo de IA de primeiro nível, comparável ao Gemini 1.5 Pro, superando Claude Big Cup em todos os aspectos
Os itens acima são apenas aperitivos do Meta, a verdadeira refeição ainda está por vir. Nos próximos meses, a Meta lançará sucessivamente uma série de novos modelos com diálogo multimodal e multilíngue, janelas de contexto mais longas e outras capacidades. Entre eles, o jogador peso-pesado com mais de 400B deverá competir com Claude 3 Super Cup. .
Endereço da experiência Llama 3: https://llama.meta.com/llama3/

Outro modelo de nível GPT-4 está aqui, Llama 3 está aberto
Comparado com o modelo Llama 2 da geração anterior, pode-se dizer que o Llama 3 atingiu um novo nível.
Graças às melhorias no pré-treinamento e pós-treinamento, os modelos de pré-treinamento e de ajuste fino de instrução lançados desta vez são os modelos mais poderosos nas escalas de parâmetros 8B e 70B atualmente. -o processo de treinamento reduziu significativamente a taxa de erro do modelo, aumenta a consistência do modelo e enriquece a diversidade de respostas.
Zuckerberg revelou certa vez em um discurso público que, considerando que os usuários não farão perguntas relacionadas à codificação Meta AI no WhatsApp, a otimização do Llama 2 nesta área não é excelente.
Desta vez, o Llama 3 alcançou melhorias revolucionárias no raciocínio, na geração de código e no seguimento de instruções, tornando-o mais flexível e fácil de usar.
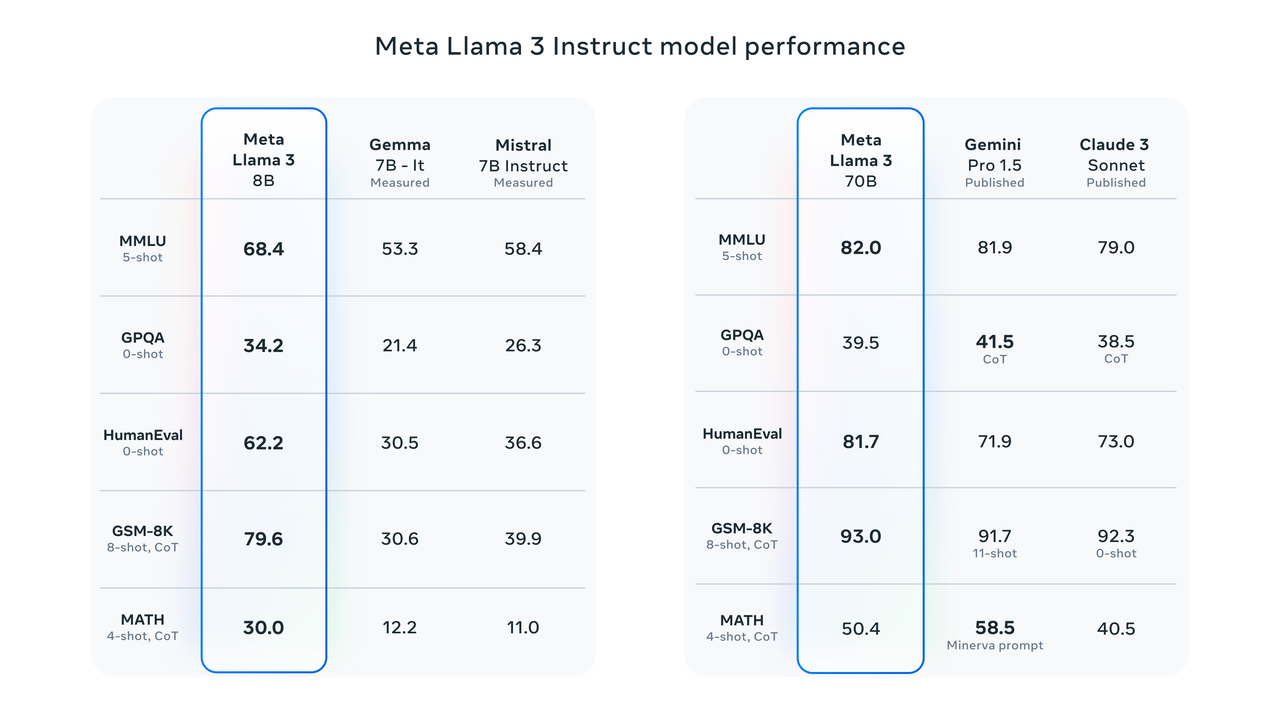
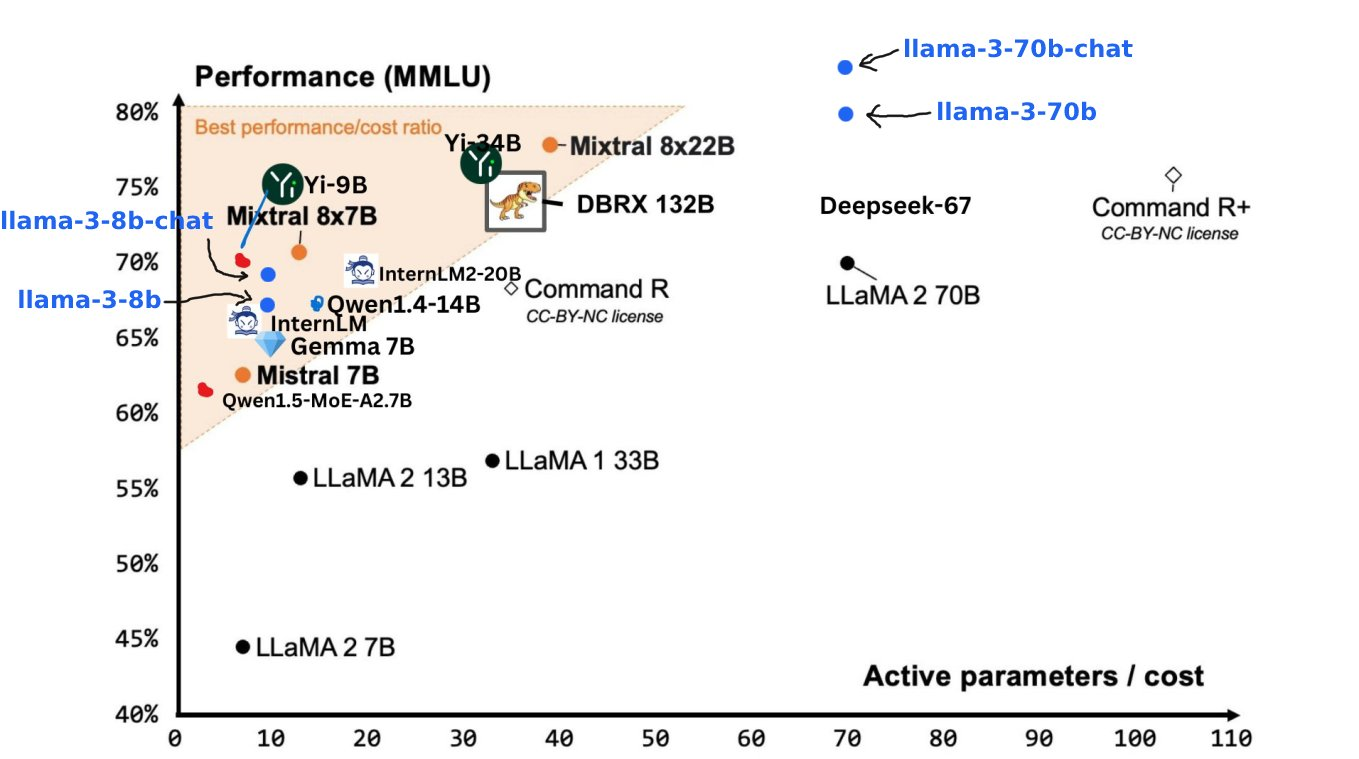
Os resultados dos testes de benchmark mostram que o Llama 3 8B tem pontuações muito mais altas do que o Google Gemma 7B e o Mistral 7B Instruct em MMLU, GPQA, HumanEval e outros testes. Nas palavras de Zuckerberg, o menor Llama 3 é basicamente tão poderoso quanto o maior Llama 2.
O Llama 3 70B está entre os principais modelos de IA. Seu desempenho geral é melhor que o do Claude 3. Comparado com o Gemini 1.5 Pro, eles são equivalentes.
Para estudar com precisão o desempenho do modelo em benchmarks, a Meta também desenvolveu um novo conjunto de dados de avaliação humana de alta qualidade.
O conjunto de avaliação contém 1.800 prompts cobrindo 12 casos de uso principais: solicitação de conselhos, brainstorming, categorização, perguntas e respostas fechadas, codificação, escrita criativa, extração, persona, perguntas e respostas abertas, raciocínio, reescrita e resumo.

Para evitar que o Llama 3 se ajustasse demais a esse conjunto de avaliação, a Meta até proibiu sua equipe de pesquisa de acessar esse conjunto de dados. Na competição individual com Claude Sonnet, Mistral Medium e GPT-3.5, Meta Llama 70B terminou a competição com uma "vitória esmagadora".
De acordo com a introdução oficial do Meta, o Llama 3 escolheu uma arquitetura Transformer de decodificador puro relativamente padrão em sua arquitetura de modelo. Comparado com o Llama 2, o Llama 3 tem várias melhorias importantes:
- O Llama 3 usa um tokenizer com vocabulário de token de 128K para codificar a linguagem de forma mais eficiente, melhorando significativamente o desempenho do modelo.
- A atenção de consulta agrupada (GQA) é usada nos modelos 8B e 70B para melhorar a eficiência de inferência do modelo Llama 3.
- O modelo é treinado em sequências de 8.192 tokens, usando máscaras para garantir que a autoatenção não ultrapasse os limites do documento.
A quantidade e a qualidade dos dados de treinamento são fatores-chave para promover o surgimento de grandes capacidades de modelos no próximo estágio.
Desde o início, o Meta Llama 3 foi projetado para ser o modelo mais poderoso possível. A Meta investe pesadamente em dados de pré-treinamento. É relatado que o Llama 3 usa mais de 15T tokens coletados de fontes públicas, o que é sete vezes o conjunto de dados usado pelo Llama 2, e os dados de código que ele contém são quatro vezes os do Llama 2.

Considerando a aplicação prática do multilíngue, mais de 5% do conjunto de dados de pré-treinamento do Llama 3 consiste em dados de alta qualidade em outros idiomas, cobrindo mais de 30 idiomas. No entanto, os funcionários da Meta também admitiram que, em comparação com o inglês, o desempenho. espera-se que um desses idiomas seja um pouco inferior.
Para garantir que o Llama 3 seja treinado com dados da mais alta qualidade, a equipe de pesquisa da Meta ainda usa filtros heurísticos, filtros NSFW, métodos de desduplicação semântica e classificadores de texto com antecedência para prever a qualidade dos dados.
É importante notar que a equipe de pesquisa também descobriu que as gerações anteriores de modelos Llama eram surpreendentemente boas na identificação de dados de alta qualidade, então eles permitiram que o Llama 2 gerasse dados de treinamento para o classificador de qualidade de texto suportado pelo Llama 3, realmente realizando "AI treinamento AI " .
Além da qualidade do treinamento, o Llama 3 também deu um salto quântico na eficiência do treinamento.
Meta revelou que para treinar o maior modelo do Llama 3, eles combinaram três tipos de paralelização: paralelização de dados, paralelização de modelo e paralelização de pipeline.
Ao treinar simultaneamente em GPUs de 16K, mais de 400 TFLOPS de utilização de computação podem ser alcançados por GPU. A equipe de pesquisa realizou execuções de treinamento em dois clusters de GPU de 24K personalizados.

Para maximizar o tempo de atividade da GPU, a equipe de pesquisa desenvolveu uma nova pilha de treinamento avançada que automatiza a detecção, o tratamento e a manutenção de erros. Além disso, a Meta melhorou muito a confiabilidade do hardware e os mecanismos silenciosos de detecção de corrupção de dados, e desenvolveu um novo sistema de armazenamento escalonável para reduzir a sobrecarga de pontos de verificação e reversões.
Essas melhorias tornam o tempo de treinamento efetivo geral superior a 95% e também tornam a eficiência de treinamento do Llama 3 cerca de três vezes maior do que a da geração anterior.
Para mais detalhes técnicos, consulte o blog oficial do Meta: https://ai.meta.com/blog/meta-llama-3/
Código aberto versus código fechado
Como "filho" do Meta, o Llama 3 está naturalmente integrado ao chatbot AI Meta AI.
Desde a conferência Meta Connect 2023 do ano passado, Zuckerberg anunciou oficialmente o lançamento do Meta AI na reunião e depois o promoveu rapidamente nos Estados Unidos, Austrália, Canadá, Cingapura, África do Sul e outras regiões.
Em entrevistas anteriores, Zuckerberg estava ainda mais confiante sobre o Meta AI equipado com o Llama 3, dizendo que seria o assistente de IA mais inteligente que as pessoas podem usar gratuitamente.
Acho que isso passará de um formato semelhante ao chatbot para um formato em que você pode simplesmente fazer uma pergunta e ele lhe dará uma resposta, e você poderá atribuir tarefas mais complexas e ele concluirá essas tarefas.
Em anexo está o endereço da experiência web Meta AI: https://www.meta.ai/

Claro, se o Meta AI "ainda não estiver disponível em seu país/região", você pode usar o canal mais simples para usar o modelo de código aberto – Hugging Face, o maior site da comunidade de código aberto de IA do mundo.
Em anexo está o endereço da experiência: https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct
Perplexity, Poe e outras plataformas também anunciaram rapidamente a integração do Llama 3 aos serviços da plataforma.

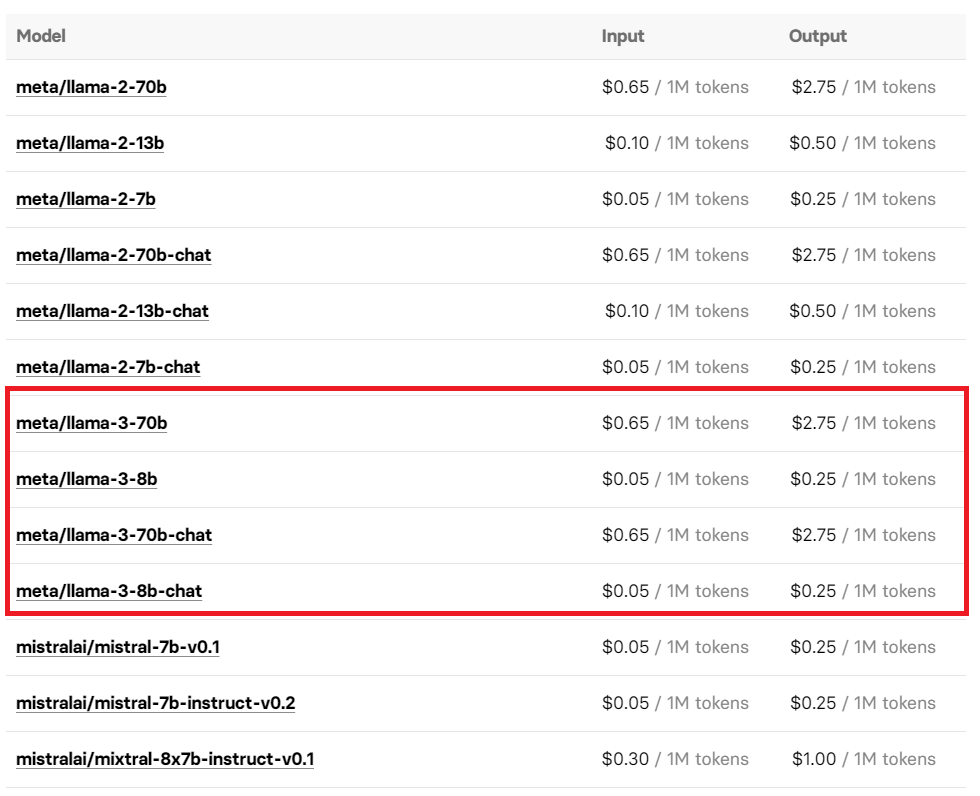
Você também pode experimentar o Llama 3 chamando a interface Replicate API da plataforma do modelo de código aberto. O preço de seu uso também foi exposto, então você pode querer usá-lo sob demanda.
Curiosamente, antes de Meta anunciar oficialmente o Llama 3, internautas perspicazes descobriram que o mercado Azure da Microsoft havia roubado a versão Llama 3 8B Instruct. No entanto, conforme a notícia se espalhava, quando os internautas se aglomeraram para tentar acessar o link novamente, tudo que consegui foi. a página "404".
Atualmente restaurado: https://azuremarketplace.microsoft.com/en-us/marketplace/apps/metagenai.meta-llama-3-8b-chat-offer?tab=overview
A chegada do Llama 3 está desencadeando uma nova tempestade de discussões na plataforma social X.
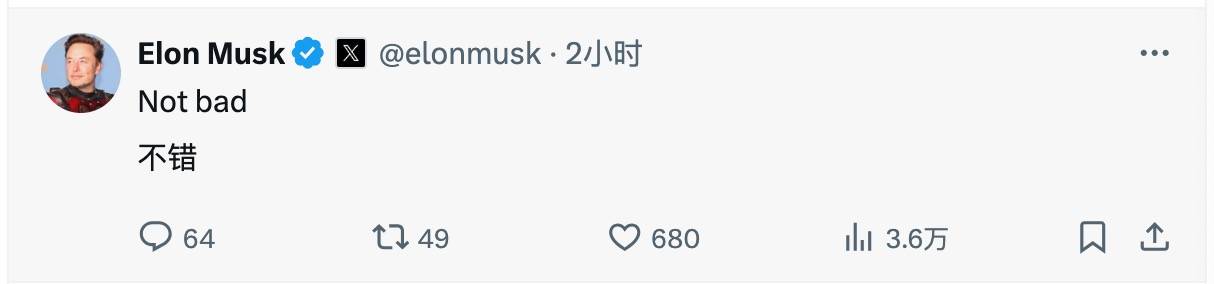
O cientista-chefe da Meta AI e vencedor do Prêmio Turing, Yann LeCun, não apenas torceu pelo lançamento do Llama 3, mas também previu mais uma vez que mais versões serão lançadas nos próximos meses. Até Musk apareceu na área de comentários e expressou seu reconhecimento e expectativas para o Llama 3 com um “Nada mal” conciso e implícito.
JIm Fan, cientista sênior da NVIDIA, concentrou sua atenção no próximo Llama 3 400B+. Em sua opinião, o lançamento do Llama 3 rompeu com o progresso tecnológico e é um símbolo do modelo de código aberto e do modelo de código fechado de ponta. .
Pelo teste de benchmark compartilhado, pode-se perceber que a força do Llama 3 400B+ é quase comparável à do Claude Extra Large Cup e da nova versão do GPT-4 Turbo. Embora ainda haja uma certa lacuna, é o suficiente para provar. que tem um lugar entre os principais modelos de grande porte.

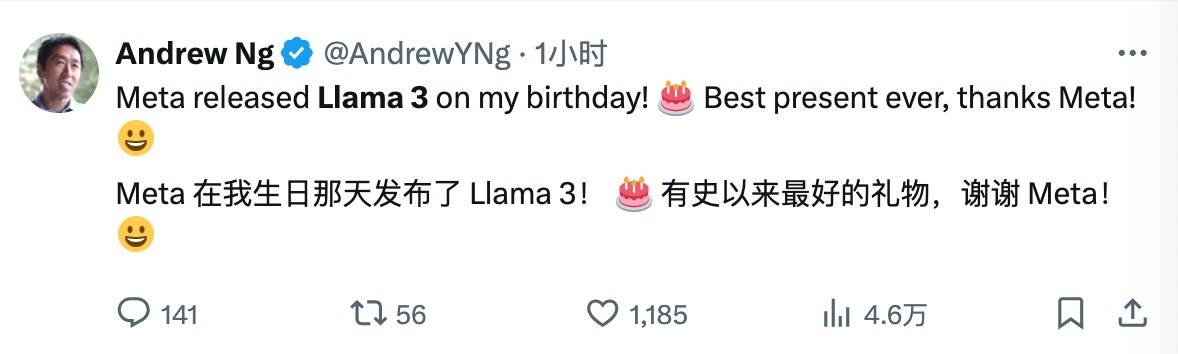
Hoje coincide com o aniversário de Andrew Ng, professor da Universidade de Stanford e grande especialista em IA. A chegada do Llama 3 é sem dúvida a forma mais especial de comemorar seu aniversário.
É preciso dizer que o modelo de código aberto atual está realmente permitindo que cem flores desabrochem e que uma centena de escolas de pensamento lutem.
No início deste ano, Zuckerberg, que tem 350 mil GPUs em mãos, descreveu em tom firme a visão da Meta em entrevista ao The Verge – comprometida com a construção de AGI (inteligência artificial geral).
Em nítido contraste com o OpenAI, que não é aberto, o Meta lançou uma investida em direção ao Santo Graal da AGI ao longo da rota do código aberto.
Como disse Zuckerberg, o Meta, que é firmemente de código aberto, não ganhou nada nesta jornada desafiadora:
Geralmente estou muito inclinado a pensar que o código aberto é bom para a comunidade e para nós porque nos beneficiamos da inovação.
No ano passado, todo o círculo da IA tem debatido incessantemente em torno da rota do código aberto ou do código fechado. Este debate foi além da comparação de vantagens e desvantagens a nível técnico e tocou na direcção central do desenvolvimento futuro da IA. Até Musk, que saiu pessoalmente, fez a diferença para o mundo com o código aberto Grok 1.0.
Não muito tempo atrás, algumas opiniões diziam que o modelo de código aberto se tornaria cada vez mais atrasado. Agora, a chegada do Llama 3 também deu um tapa retumbante na cara dessa visão pessimista.
No entanto, embora o Llama 3 traga algum alívio ao modelo de código aberto, este debate sobre código aberto versus código fechado está longe de terminar.
Afinal, o GPT-4.5/5, que se prepara secretamente para ser lançado, pode pôr fim a este debate prolongado com um desempenho incomparável neste verão.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (ID do WeChat: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
