
Revelando o modelo de geração de vídeo mais poderoso, Sora, como o OpenAI consegue uma cena em um minuto?

Esta manhã, a OpenAI retirou a ferramenta de geração de vídeo de IA Sora de seu “arsenal de munições”, ocupando instantaneamente as principais manchetes.
Até Musk, que sempre esteve em desacordo com a OpenAI, está disposto a admitir o poder de Sora e elogiá-lo: “Nos próximos anos, os humanos criarão obras notáveis com a ajuda do poder da IA”.
O poder do Sora reside em sua capacidade de gerar vídeos coerentes e suaves de até 60 segundos com base em descrições de texto, que contêm cenas delicadas e complexas, expressões vívidas de personagens e movimentos de câmera complexos.
Comparado com outros vídeos que só podem gerar vídeos de apenas um dígito, a duração de um minuto de Sora sem dúvida tem o efeito de virar a mesa.
Mais importante ainda, Sora mostrou o melhor nível em termos de autenticidade de vídeo, duração, estabilidade, consistência, resolução ou compreensão de texto. Vamos primeiro aproveitar os videoclipes de demonstração lançados oficialmente.
Aviso: A bela e nevada cidade de Tóquio está movimentada. A câmera se move pelas ruas movimentadas da cidade, seguindo várias pessoas aproveitando o lindo clima de neve e fazendo compras em barracas próximas. Lindas pétalas de sakura voam ao vento junto com flocos de neve.
Neste vídeo, um casal é visto da perspectiva de um drone caminhando por uma rua movimentada da cidade, com lindas pétalas de flores de cerejeira dançando no ar acompanhadas por flocos de neve.
Enquanto outras ferramentas ainda lutam para manter uma única lente estável, Sora conseguiu alternar suavemente várias lentes, e a coerência da troca de lentes e a consistência dos objetos estão muito à frente, o que é um verdadeiro golpe na redução da dimensionalidade. 

▲De @gabor
No passado, gravar um vídeo desse tipo poderia exigir muito tempo e energia em uma série de tarefas tediosas, como criação de roteiro e design de cena. Agora, com apenas uma simples descrição de texto, Sora pode gerar completamente uma cena tão grande, e os praticantes relevantes podem ter começado a tremer.
O internauta @debarghya_das criou este trailer de mais de 20 segundos em 15 minutos usando a edição OpenAI Sora, a voz de David Attenborough no Eleven Labs e alguns samples de música natural do Youtube no iMovie.

Como Sora consegue seus efeitos poderosos?
A OpenAI também divulgou um relatório técnico detalhado sobre o Sora, apresentando os princípios técnicos e aplicações por trás dele.
Então, como Sora conseguiu esse avanço? Inspirado na experiência prática bem-sucedida do LLM, o OpenAI apresenta códigos de incorporação de patches visuais (patches), uma representação de dados visuais altamente escalável e eficaz que pode melhorar significativamente a capacidade dos modelos generativos de lidar com diversos dados de vídeo e imagem.

Em um espaço de alta dimensão, o OpenAI primeiro comprime os dados de vídeo em um espaço latente de baixa dimensão e depois os decompõe em incorporações espaço-temporais, convertendo assim o vídeo em uma série de blocos de codificação.
Em seguida, a OpenAI treinou uma rede projetada especificamente para reduzir a dimensionalidade dos dados visuais. A rede recebe um vídeo bruto como entrada e produz uma representação latente que é comprimida no tempo e no espaço. É dentro desse espaço latente comprimido que Sora é treinado e gera vídeos dentro desse espaço.
Além disso, a OpenAI treinou um modelo de decodificador que pode restaurar essas representações latentes em imagens de vídeo em nível de pixel.
Ao processar a entrada de vídeo compactada, os pesquisadores conseguiram extrair uma série de patches espaço-temporais, que desempenham um papel semelhante aos Transformer Tokens no modelo.
Usando uma representação baseada em patches, Sora pode se adaptar a vídeos e imagens de diferentes resoluções, durações e proporções. Ao gerar novo conteúdo de vídeo, esses patches inicializados aleatoriamente podem ser organizados em uma grade de acordo com o tamanho necessário. Controle o tamanho e forma do seu vídeo final.

Embora o princípio acima pareça bastante complicado, na verdade, a nova tecnologia usada pela OpenAI – código de incorporação de bloco visual (referido como bloco visual) – é como organizar um monte de blocos de construção desorganizados em uma pequena caixa. Dessa forma, mesmo que haja muitos blocos de construção, você poderá encontrar facilmente os blocos de construção necessários, desde que encontre esta pequena caixa.
Como os dados de vídeo são convertidos em pequenos quadrados, quando o OpenAI fornece a Sora uma nova tarefa de vídeo, eles primeiro extraem alguns pequenos quadrados contendo informações temporais e espaciais do vídeo. Esses pequenos quadrados são então entregues a Sora para gerar novos vídeos com base nessas informações.
Desta forma, o vídeo pode ser montado novamente como um quebra-cabeça. A vantagem disso é que o computador pode aprender e processar uma variedade de diferentes tipos de fotos e vídeos com mais rapidez.
À medida que Sora foi treinado mais profundamente, os pesquisadores da OpenAI também descobriram que a qualidade da amostra melhorou significativamente à medida que a quantidade de computação de treinamento aumentou. A OpenAI descobriu que treinar diretamente no tamanho original dos dados tem várias vantagens:
- Sora não corta o material durante o treinamento, permitindo que Sora crie conteúdo diretamente de acordo com a proporção nativa de diferentes dispositivos.
- O treinamento na proporção nativa do vídeo pode melhorar significativamente a composição e a qualidade do layout do vídeo.

Além disso, Sora possui os seguintes recursos:
O treinamento de um sistema de geração de texto para vídeo requer um grande número de vídeos com legendas textuais. OpenAI aplica a tecnologia de reanotação introduzida no DALL·E 3 aos vídeos.
Semelhante ao DALL·E 3, o OpenAI usa GPT para converter os prompts curtos do usuário em instruções mais detalhadas e depois os envia para o modelo de vídeo, permitindo que Sora gere vídeos de alta qualidade.
Além de converter texto, Sora também pode aceitar entradas de imagens ou vídeos existentes. Este recurso permite que Sora conclua uma variedade de tarefas de edição de imagens e vídeos, como criar vídeos em loop contínuo, adicionar efeitos de animação a imagens estáticas, estender o tempo de reprodução de vídeos, etc.
Uma imagem realista de nuvens formando a palavra "SORA".


Num salão histórico ricamente decorado, uma enorme onda está prestes a atingir. Os dois surfistas aproveitaram a oportunidade e surfaram as ondas com maestria.


Sora pode mudar o estilo e o ambiente de um vídeo sem nenhum exemplo prévio. Até dois vídeos com estilos completamente diferentes podem ser conectados sem problemas.

Sora também pode gerar imagens. A equipe de pesquisa cria imagens de vários tamanhos, organizando blocos de ruído gaussianos em uma grade espacial com intervalo de tempo de apenas um quadro. A resolução máxima chega a 2048×2048.

O verdadeiro OpenAI também admitiu francamente as limitações atuais do Sora, como sua incapacidade de simular os efeitos físicos de cenas complexas e compreender algumas relações causais específicas. Por exemplo, ele não pode simular com precisão interações físicas básicas, como quebra de vidro.

▲ Correndo na direção oposta
Mas a OpenAI acredita firmemente que as capacidades atuais do Sora mostram que a expansão contínua dos modelos de vídeo é um caminho promissor para o desenvolvimento de simuladores capazes que possam simular os mundos físico e digital e os objetos, animais e humanos dentro deles.
Modelos mundiais, a próxima direção da IA?
A OpenAI descobriu que, quando treinado em escala, Sora exibe um conjunto atraente de capacidades emergentes que podem simular pessoas, animais e ambientes do mundo real até certo ponto.
Esses recursos não são baseados em predefinições específicas de espaço ou objetos tridimensionais, mas são orientados por dados em grande escala.
- Coerência no espaço tridimensional
Sora pode gerar vídeos com mudanças dinâmicas de perspectiva. Quando a posição e o ângulo da câmera mudam, os personagens e os elementos da cena no vídeo podem se mover de forma coerente no espaço tridimensional. - Continuidade de longa distância e persistência de objetos Sora mantém a continuidade do vídeo por longos períodos de tempo, mesmo quando pessoas, animais ou objetos são obscurecidos ou movidos para fora do quadro. Da mesma forma, pode mostrar o mesmo personagem várias vezes na mesma amostra de vídeo e garantir uma aparência consistente.
- Simulação do mundo digital
Sora também pode simular processos digitais, como videogames, simplesmente mencionando as palavras “Minecraft” para ativar suas habilidades relacionadas.
A OpenAI considera Sora como “a base de modelos que podem compreender e simular o mundo real” e acredita que suas capacidades “serão um marco importante na realização da AGI”.
Sobre a chegada de Sora, o cientista sênior da NVIDIA Jim Fan disse:
Se você acha que o Sora da OpenAI é uma ferramenta para experimentação criativa, como o DALL·E, você pode querer reconsiderar.
Sora é na verdade um mecanismo de simulação física baseado em dados que pode simular mundos reais ou fictícios. Este simulador aprende renderização complexa de imagens, comportamento físico "intuitivo", recursos de planejamento de longo prazo e compreensão de nível semântico por meio de cálculos de eliminação de ruído e gradiente.
A base desta capacidade de modelo é o modelo universal mundial, que é um sistema de inteligência artificial, cujo objetivo é construir um módulo de rede neural que possa atualizar o estado para memorizar e modelar o ambiente.
Este modelo é capaz de prever a próxima observação possível com base nas observações atuais (como imagens, estados, etc.) e ações futuras. Ele simula possíveis eventos futuros no meio ambiente, aprendendo as leis e o bom senso do mundo.

Na verdade, o modelo mundial não é um conceito novo. Já em dezembro do ano passado, a Runway, líder em geração de vídeo de IA, anunciou oficialmente que construiria um modelo mundial universal com o objetivo de criar uma espécie de LLM diferente. do LLM existente e pode ser mais realista.Sistemas de inteligência artificial que simulam o mundo real.
Especificamente, a ideia central do modelo mundial é aprender como o mundo funciona memorizando a experiência histórica e, em seguida, prever eventos que podem ocorrer no futuro. Por exemplo, a partir de um vídeo de um objeto em queda, o modelo pode prever o próximo quadro com base na imagem atual, aprendendo assim as leis físicas do movimento do objeto.
O vencedor do Prêmio Turing, Yann LeCun, também propôs um conceito semelhante e criticou grandes modelos baseados em autorregressão generativa probabilística, como o GPT, acreditando que tais modelos não podem resolver o problema da alucinação. LeCun e sua equipe prevêem até que modelos como o GPT poderão ficar obsoletos nos próximos cinco anos.
Os modelos mundiais podem ser vistos como uma direção de pesquisa no campo da inteligência artificial que tenta criar uma IA mais próxima do nível da inteligência humana. Ao simular e aprender com ambientes e eventos do mundo real, os modelos mundiais têm o potencial de levar a IA a níveis mais elevados de capacidades de simulação e previsão.
Em fevereiro, Justine Moore, sócia da conhecida empresa de capital de risco a16z, conduziu uma análise aprofundada da situação atual no campo da geração de vídeo por IA. Nos dois anos desde que a IA generativa entrou gradualmente aos olhos do público, o campo da geração de vídeo por IA deu início a um cenário próspero onde cem flores desabrocham e cem escolas de pensamento estão em disputa.
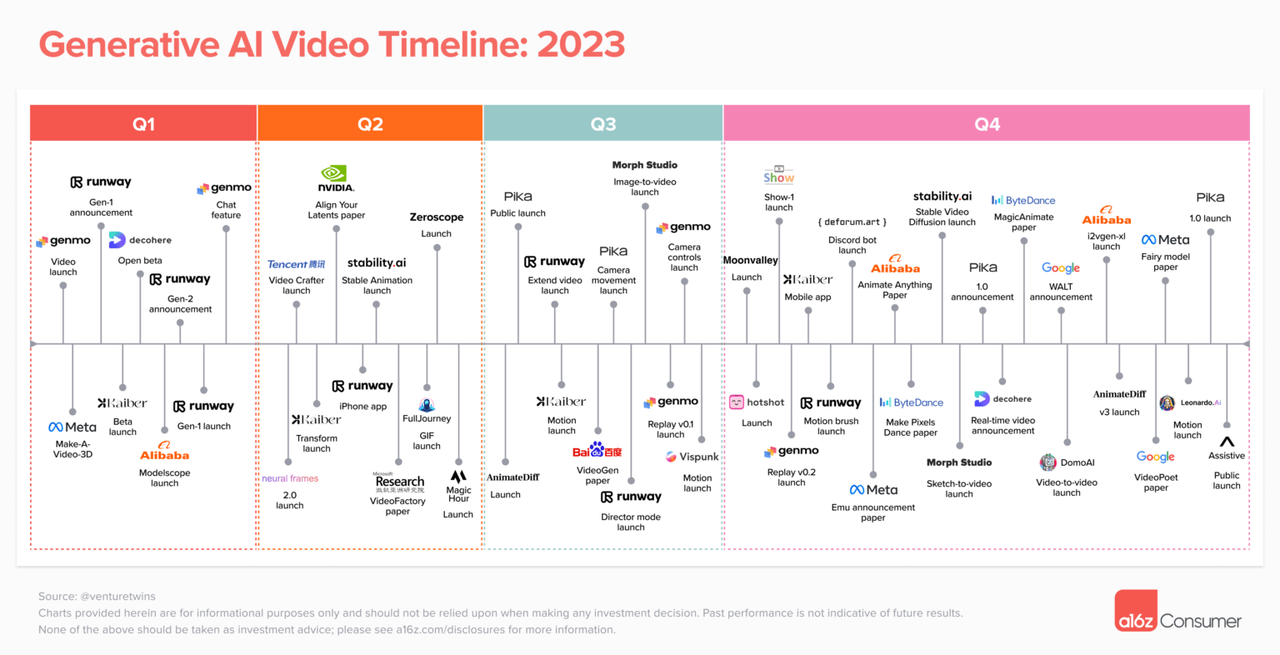
Com a adição do OpenAI Sora, o campo de geração de vídeo de IA causará grandes ondas, e as plataformas convencionais existentes, como Runway, Pika e Stable Video Diffusion, poderão ser afetadas.
Ao mesmo tempo, as regras do jogo para criadores independentes serão completamente alteradas: qualquer pessoa com criatividade e ideias poderá usar o Sora para gerar seu próprio conteúdo de vídeo. A redução do limiar para a criação também significa que os criadores independentes darão início a uma era de ouro.
Como dito em "O problema dos três corpos", "Não importa." Independentemente da atual situação competitiva, o campo da geração de vídeo por IA pode ser subvertido por novas tecnologias e inovações. E a entrada de Sora é apenas o começo, longe de ser o fim.
# Bem-vindo a seguir a conta pública oficial do WeChat de aifaner: aifaner (WeChat ID: ifanr).Mais conteúdo interessante será fornecido a você o mais rápido possível.
