
Fazer um vídeo com a boca está mesmo chegando! Este novo aplicativo, Meta, é tão ultrajante
Este ano é um ano de grande progresso para a IA no campo da produção de imagem e vídeo.
Alguém levou o prêmio de arte digital com uma imagem gerada por IA e derrotou um grupo de artistas humanos; existem aplicativos como o Tiktok que geram imagens por meio de entrada de texto e as transformam em fundo de tela verde de vídeos curtos; existem novos produtos que podem do text Gere vídeo diretamente e perceba diretamente o efeito de "fazer vídeo com a boca".
O produto desta vez vem da Meta, que cultiva profundamente a inteligência artificial há muitos anos, e foi loucamente ridicularizada por causa do metaverso há algum tempo.

▲ O Meta Metaverse foi ridicularizado descontroladamente
Só que desta vez, você não pode zombar, porque realmente tem um pequeno avanço.
Texto para vídeo, o que pode ser feito
Agora, você pode mover sua boca para fazer um vídeo.
Embora isso seja um pouco exagerado, o Make-A-Video da Meta desta vez provavelmente está realmente se movendo em direção a esse objetivo.

O que o Make-A-Video pode fazer atualmente é:
- Text-to-video – transforme sua imaginação em vídeos reais e únicos
- Converta imagens diretamente em vídeo – deixe uma única imagem ou duas imagens se moverem naturalmente
- Vídeo Gerando Vídeo Estendido – Insira um vídeo para criar uma variante de vídeo
Em termos de geração direta de vídeo a partir de texto, o Make-A-Video derrotou muitos estudantes profissionais de design de animação. Pelo menos pode fazer qualquer estilo, e o custo de produção é muito baixo.
Embora o site oficial não permita que você gere diretamente uma experiência de vídeo, você pode enviar suas informações pessoais primeiro e, em seguida, o Make-A-Video compartilhará todos os desenvolvimentos com você primeiro.

Não há muitos casos que podem ser vistos até agora, e os casos exibidos no site oficial ainda têm alguns lugares estranhos nos detalhes. Mas de qualquer forma, o fato de o texto poder ser transformado diretamente em vídeo é uma melhoria em si.
Um ursinho de pelúcia está desenhando um autorretrato, e você pode ver a projeção não natural da mão do urso na parte sombreada do papel.

Robôs dançam na Times Square.

O gato está segurando o controle remoto da TV para mudar o canal. As garras do gato são muito semelhantes às mãos humanas, e às vezes parece um pouco assustador assistir.

E uma preguiça peluda com um chapéu de malha laranja brinca com um laptop, a luz da tela do computador em seus olhos.

Os acima são estilos surreais, e os casos mais parecidos com a realidade são mais fáceis de usar.
Os cases mostrados pelo Make-A-Video são bons se focarem apenas em áreas locais, como o close-up do artista pintando na tela, o cavalo bebendo água e os peixinhos nadando no recife de coral.



Mas um jovem casal um pouco mais realista andando na chuva forte é muito estranho. A parte superior do corpo está bem, mas os pés da parte inferior do corpo estão piscando, às vezes esticados, como um filme de fantasmas.

Há também vídeos em estilo pintura de naves espaciais pousando em Marte, casais de smoking presos em chuvas torrenciais, luz do sol nas mesas e bonecos pandas em movimento. Em termos de detalhes, esses vídeos não são perfeitos, mas apenas pelo efeito inovador da AI text-to-video, eles ainda são incríveis.




Pinturas estáticas também podem ser animadas com a ajuda do Make-A-Video – o barco está se movendo nas grandes ondas.

As tartarugas estão nadando no mar. A imagem inicial é muito natural, mas depois fica mais como um recorte de tela verde, o que não é natural.
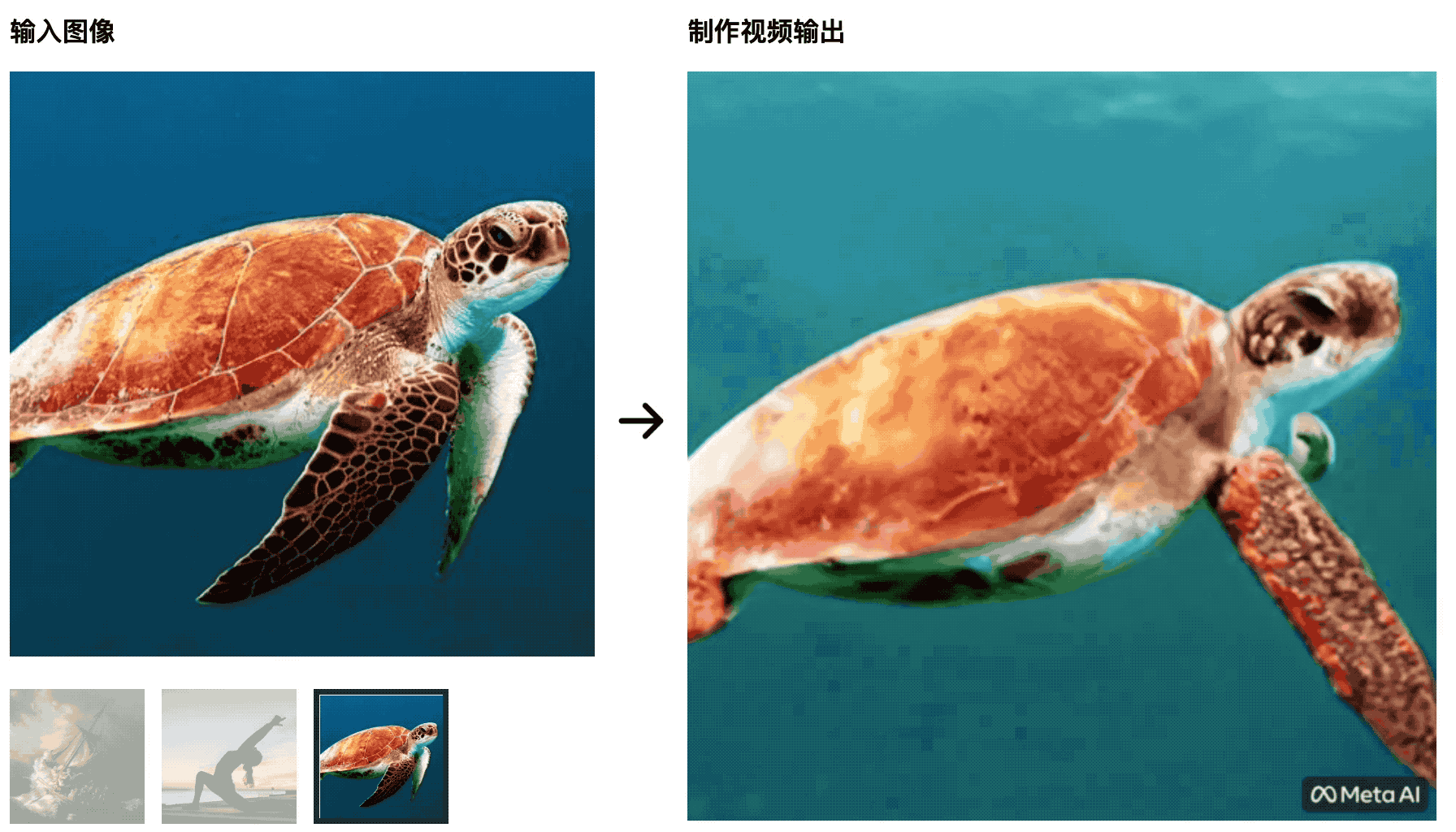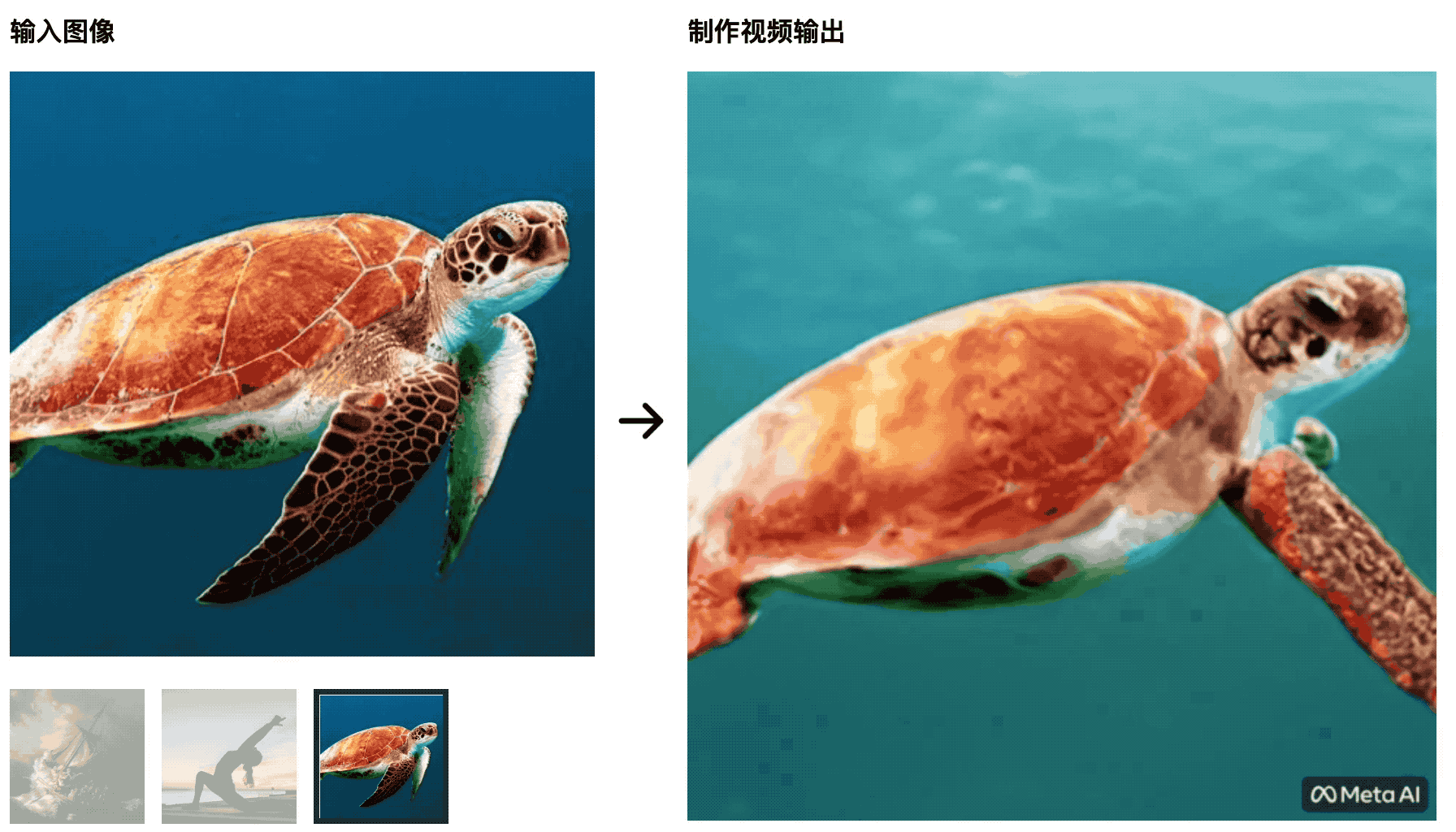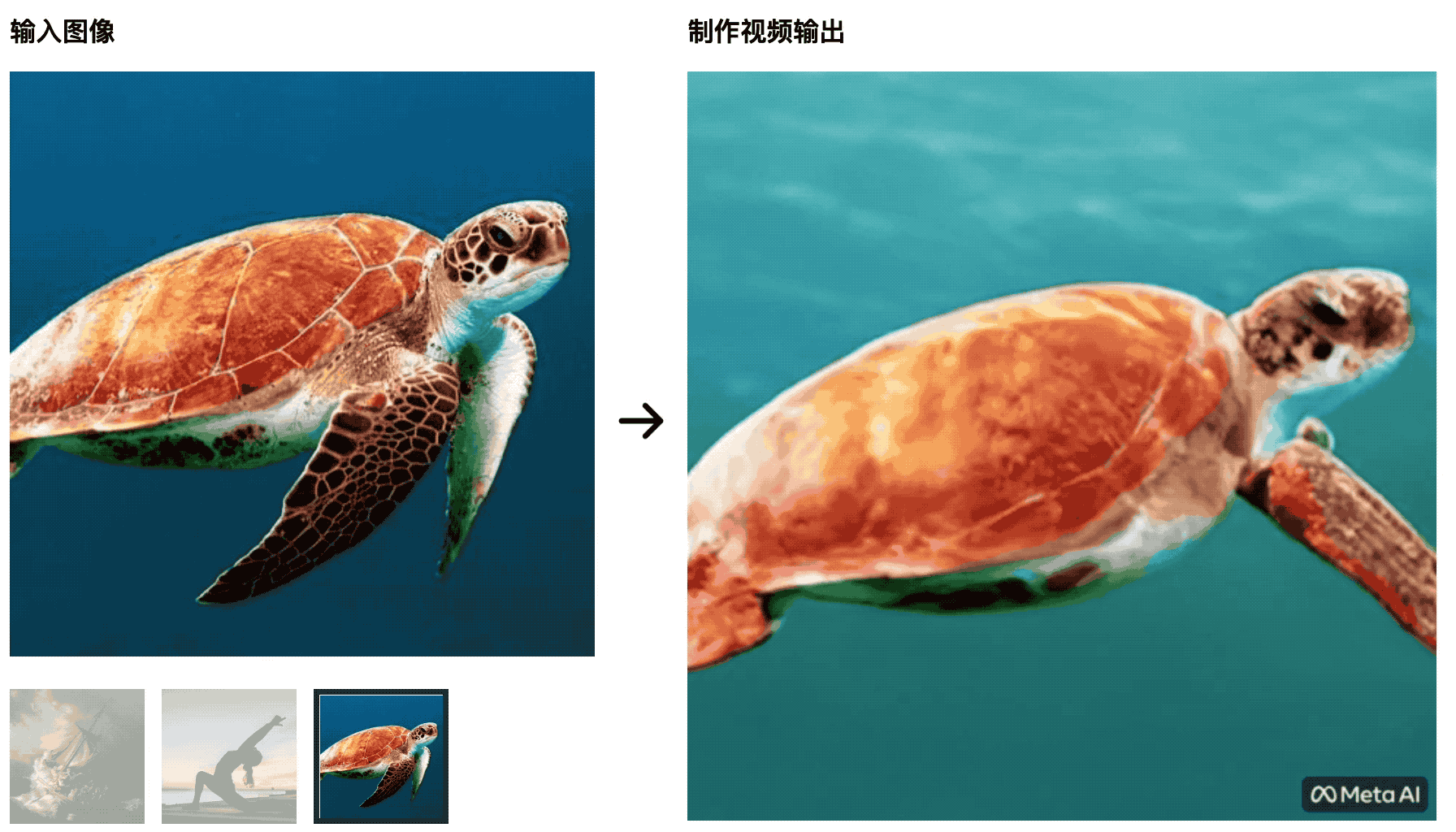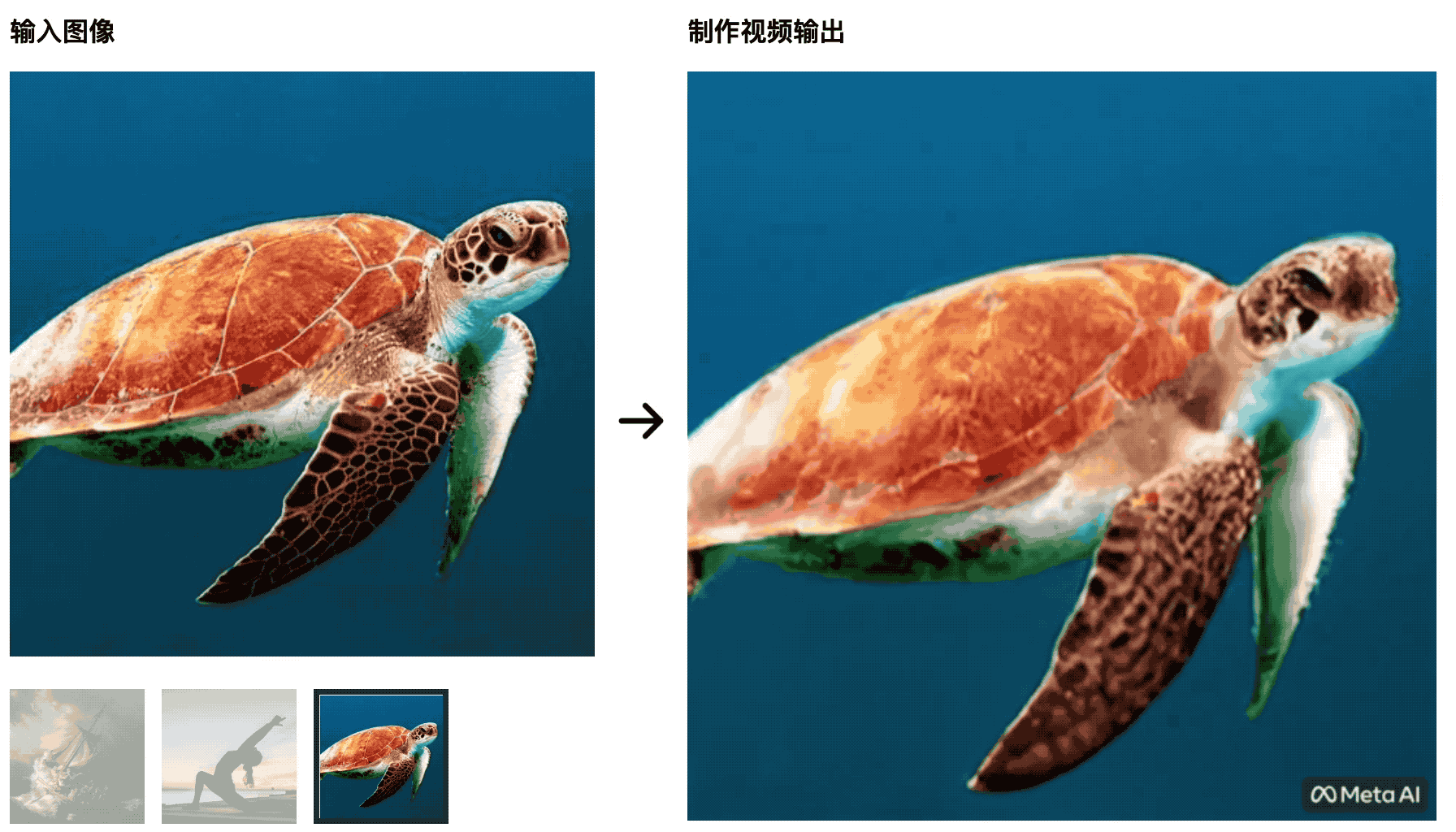
O treinador de ioga estica seu corpo no sol nascente e o tapete de ioga muda com as mudanças do vídeo – essa IA não será capaz de derrotar os alunos que estudam produção de cinema e televisão, e as variáveis de controle não são bem feitas.

Por fim, insira um vídeo para imitar seu estilo para criar variantes de vídeo. Existem também 3 casos.
Uma das mudanças é relativamente menos refinada. O vídeo dos astronautas voando no espaço foi transformado em uma versão um pouco menos estética de 4 versões grosseiras do vídeo.

Há algumas mudanças surpreendentes no vídeo do ursinho dançando, pelo menos a postura da dança mudou.

Quanto ao último vídeo do coelho comendo capim, é o mais "anneng me distingue como macho e fêmea". É difícil reconhecer quem é o vídeo inicial nos últimos 5 vídeos, e parece muito harmonioso.

Assim que o texto para a imagem for progredido, o vídeo está chegando
Em " Depois do AlphaGo, ele subverte completamente a cognição humana novamente ", uma vez apresentamos o aplicativo de geração de imagens DALL·E. Alguém o usou para criar imagens para competir com artistas humanos e, eventualmente, vencer.
O Make-A-Video que vemos agora pode ser considerado uma versão em vídeo do DALL·E (versão primária) – é como o DALL·E há 18 meses, com um grande avanço, mas o efeito atual pode não fazer o as pessoas estão satisfeitas.

▲ Pintura estendida criada por DALL·E
Pode-se até dizer que é um produto que se apoia nos ombros da gigante DALL·E e faz conquistas. Comparado com imagens geradas por texto, o Make-A-Video não fez muitas mudanças novas no backend.
“Vimos que os modelos que descrevem imagens geradas por texto também foram surpreendentemente eficazes na geração de vídeos curtos”, disseram os pesquisadores em seu artigo.

▲ Trabalhos premiados que descrevem imagens geradas por texto
Atualmente, os vídeos produzidos pela Make-A-Video têm 3 vantagens:
- Treinamento acelerado de modelos T2V (texto para vídeo)
- Não há necessidade de dados emparelhados de texto para vídeo
- O vídeo convertido herda o estilo da imagem/vídeo original
Essas imagens certamente têm desvantagens, e a falta de naturalidade mencionada acima é real. E eles não são como os vídeos nascidos nesta época, a qualidade da imagem é embaçada, o movimento é rígido, a correspondência de som não é suportada, a duração de um vídeo não é superior a 5 segundos e a resolução é de 64 x 64px.

▲ Este vídeo tem alguns frames da língua e das mãos do cachorro que são muito estranhos
O primeiro modelo CogVideo que pode sintetizar diretamente vídeo a partir de texto, lançado há alguns meses por uma equipe de pesquisa da Universidade de Tsinghua e do Instituto de Pesquisa Zhiyuan (BAAI), também tem esse problema. Com base na arquitetura Transformer pré-treinada em larga escala, ele propõe uma estratégia de treinamento hierárquico de taxa de vários quadros, que pode alinhar de forma eficiente o texto e os clipes de vídeo, mas não pode suportar escrutínio.
Mas quem pode dizer que 18 meses depois, o Make-A-Video e o CogVideo não farão vídeos melhores do que a maioria?

▲ Vídeo gerado por CogVideo – atualmente suporta apenas geração chinesa
Embora não existam muitas ferramentas de conversão de texto em vídeo lançadas, há muitas a caminho. Após o lançamento do Make-A-Video, os desenvolvedores da start-up StabilityAI declararam publicamente: "Nosso (aplicativo de texto para vídeo) será mais rápido e melhor e aplicável a mais pessoas".
A competição é melhor, e a função de conversão de texto em imagem cada vez mais realista é a melhor prova.
#Bem-vindo a prestar atenção à conta oficial do WeChat de Aifaner: Aifaner (WeChat: ifanr), conteúdo mais interessante será trazido para você o mais rápido possível.
