
Índice de banco de dados: uma introdução para iniciantes
"Índice de banco de dados" refere-se a um tipo especial de estrutura de dados que acelera a recuperação de registros de uma tabela de banco de dados. Os índices de banco de dados garantem que você possa localizar e acessar os dados em uma tabela de banco de dados com eficiência, sem ter que pesquisar cada linha sempre que uma consulta de banco de dados é processada.
Um índice de banco de dados pode ser comparado ao índice de um livro. Os índices nos bancos de dados apontam para o registro que você está procurando no banco de dados, assim como a página de índice de um livro aponta para o tópico ou capítulo desejado.
No entanto, embora os índices de banco de dados sejam essenciais para uma consulta e acesso rápido e eficiente aos dados, eles ocupam gravações adicionais e espaço de memória.
O que é um índice?
Os índices de banco de dados são tabelas de pesquisa especiais que consistem em duas colunas. A primeira coluna é a chave de pesquisa e a segunda é o ponteiro de dados. As chaves são os valores que você deseja pesquisar e recuperar de sua tabela de banco de dados, e o ponteiro ou referência armazena o endereço do bloco de disco no banco de dados para aquela chave de pesquisa específica. Os campos-chave são classificados para acelerar a operação de recuperação de dados para todas as suas consultas.
Por que usar indexação de banco de dados?
Vou mostrar os índices do banco de dados de uma forma simplificada aqui. Vamos supor que você tenha uma tabela de banco de dados dos oito funcionários que trabalham em uma empresa e deseja pesquisar as informações da última entrada da tabela. Agora, para encontrar a entrada anterior, você precisa pesquisar cada linha do banco de dados.
No entanto, suponha que você classificou a tabela em ordem alfabética com base no primeiro nome dos funcionários. Portanto, aqui as chaves de indexação são baseadas na "coluna de nome". Nesse caso, se você pesquisar a última entrada, “ Zack ”, poderá pular para o meio da tabela e decidir se nossa entrada vem antes ou depois da coluna.
Como você sabe, ele virá após a linha do meio e você pode novamente dividir as linhas após a linha do meio pela metade e fazer uma comparação semelhante. Dessa forma, você não precisa percorrer cada linha para encontrar a última entrada.
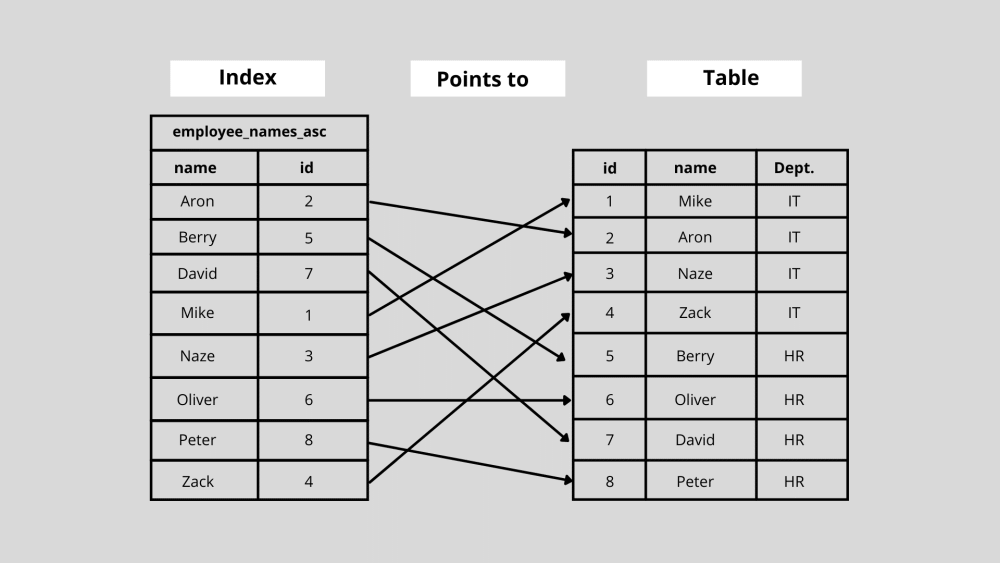
Se a empresa tivesse 1.000.000 de funcionários e a última entrada fosse “Zack”, você teria que pesquisar 50.000 linhas para encontrar o nome dele. Já com a indexação alfabética, você pode fazer isso em algumas etapas. Agora você pode imaginar como a pesquisa de dados e o acesso podem se tornar mais rápidos com a indexação do banco de dados.
Diferentes métodos de organização de arquivos para índices de banco de dados
A indexação depende muito do mecanismo de organização de arquivos usado. Normalmente, existem dois tipos de métodos de organização de arquivos usados na indexação de banco de dados para armazenar dados. Eles são discutidos abaixo:
1. Arquivo de índice ordenado: este é o método tradicional de armazenamento de dados de índice. Nesse método, os valores-chave são classificados em uma ordem específica. Os dados em um arquivo de índice ordenado podem ser armazenados de duas maneiras.
- Índice esparso: neste tipo de indexação, uma entrada de índice é criada para cada registro.
- Índice denso: na indexação densa, uma entrada de índice é criada para alguns registros. Para localizar um registro neste método, primeiro você deve encontrar o valor da chave de pesquisa mais significativo a partir das entradas de índice que são menores ou iguais ao valor da chave de pesquisa que você está procurando.
2. Organização de arquivos hash: Neste método de organização de arquivos, uma função hash determina o local ou bloco de disco onde um registro é armazenado.
Tipos de indexação de banco de dados
Geralmente, existem três métodos de indexação de banco de dados. Eles são:
- Indexação em cluster
- Indexação não agrupada
- Indexação multinível
1. Indexação em cluster
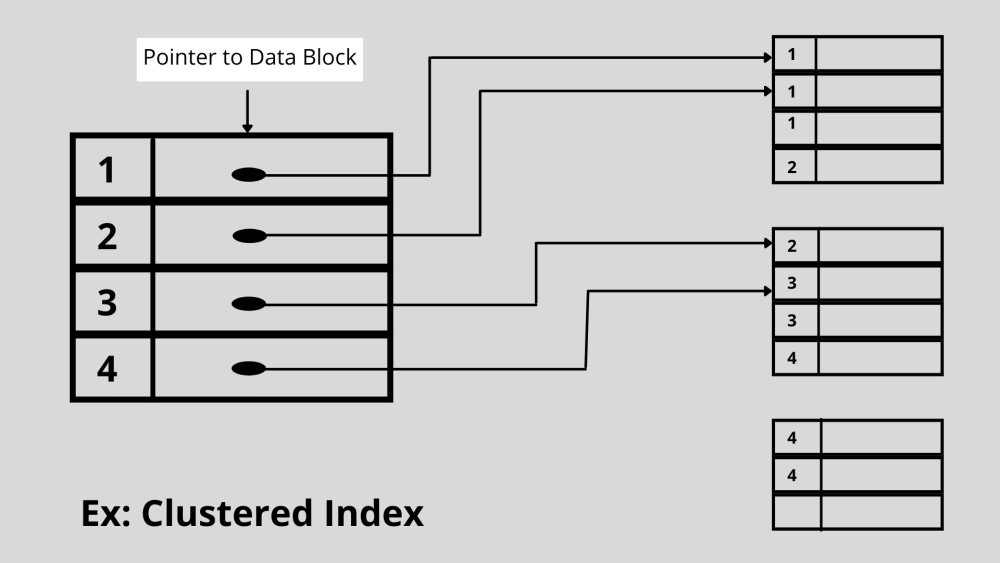
Na indexação de cluster, um único arquivo pode armazenar mais de dois registros de dados. O sistema mantém os dados reais na indexação agrupada em vez dos ponteiros. A pesquisa é econômica com indexação em cluster, pois armazena todos os dados relacionados no mesmo lugar.
Um índice de cluster usa arquivos de dados ordenados para se definir. Além disso, juntar várias tabelas de banco de dados é muito comum com esse tipo de indexação.
Também é possível criar um índice com base em colunas não primárias que não são exclusivas para cada chave. Nessas ocasiões, ele combina várias colunas para formar os valores de chave exclusivos para índices agrupados.
Portanto, em resumo, os índices de agrupamento são onde tipos de dados semelhantes são agrupados e os índices são criados para eles.
Exemplo: suponha que haja uma empresa com mais de 1.000 funcionários em 10 departamentos diferentes. Nesse caso, a empresa deve criar indexação de cluster em seu DBMS para indexar os funcionários que trabalham no mesmo departamento.
Cada cluster com funcionários trabalhando no mesmo departamento será definido como um único cluster e os indicadores de dados em índices se referirão ao cluster como uma entidade inteira.
2. Indexação não agrupada
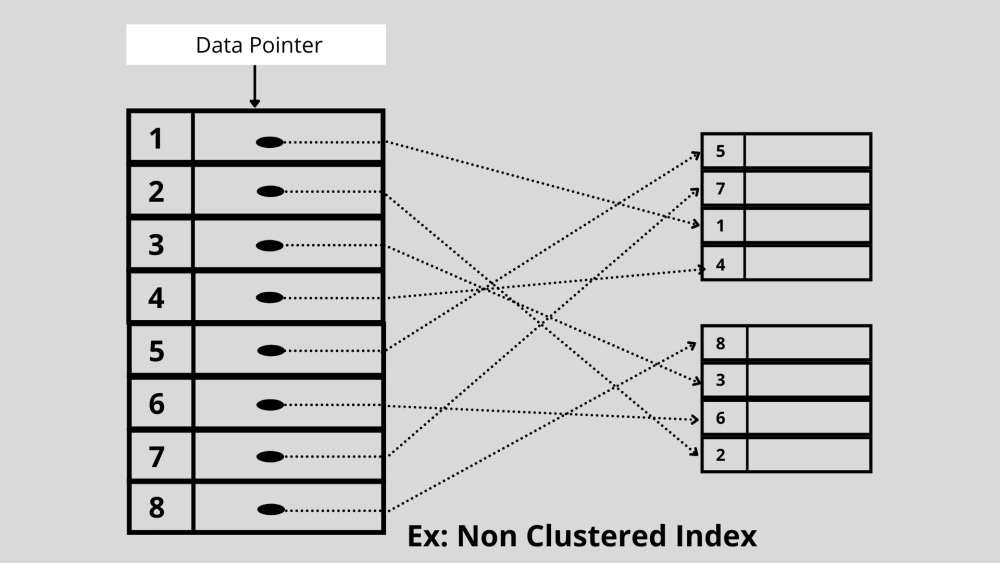
A indexação não agrupada se refere a um tipo de indexação em que a ordem das linhas do índice não é a mesma de como os dados originais são armazenados fisicamente. Em vez disso, um índice não agrupado aponta para o armazenamento de dados no banco de dados.
Exemplo: a indexação não agrupada é semelhante a um livro que possui uma página de conteúdo ordenada. Aqui, o indicador de dados ou referência é a página de conteúdo ordenada que é classificada em ordem alfabética, e os dados reais são as informações nas páginas do livro. A página de conteúdo não armazena as informações nas páginas do livro em sua ordem.
3. Indexação multinível
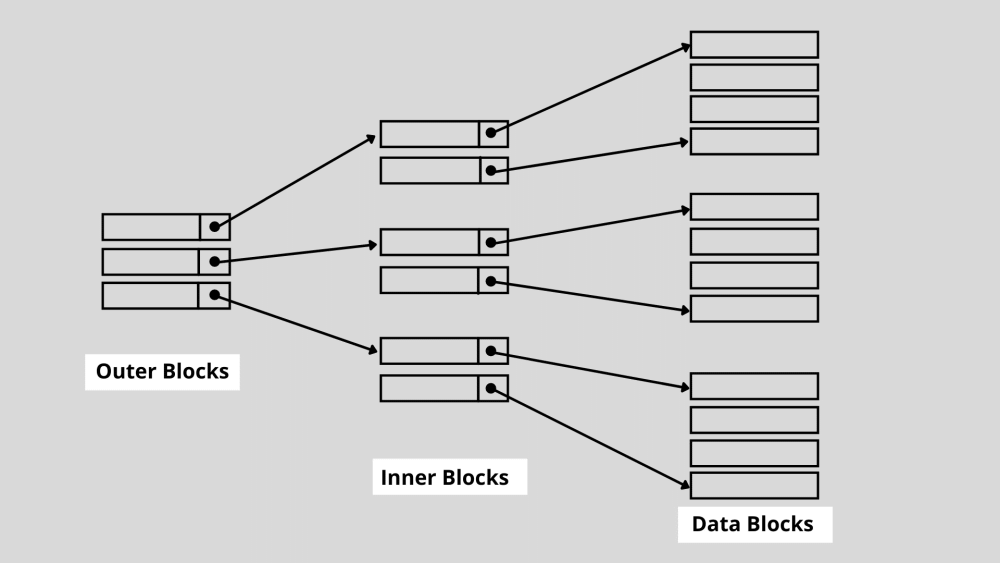
A indexação multinível é usada quando o número de índices é muito alto e não pode armazenar o índice primário na memória principal. Como você deve saber, os índices do banco de dados incluem chaves de pesquisa e indicadores de dados. Quando o tamanho do banco de dados aumenta, o número de índices também aumenta.
No entanto, para garantir uma operação de pesquisa rápida, os registros de índice devem ser mantidos na memória. Se um índice de nível único for usado quando o número do índice for alto, é improvável que armazene esse índice na memória devido ao seu tamanho e aos vários acessos.
É aqui que a indexação multinível entra em jogo. Essa técnica divide o índice de nível único em vários blocos menores. Após quebrar, o bloco de nível externo torna-se tão pequeno que pode ser facilmente armazenado na memória principal.
O que é fragmentação de índice SQL?
Quando qualquer ordem das páginas de índice não corresponde à ordem física no arquivo de dados, causa a fragmentação do índice SQL. Inicialmente, todos os índices SQL residem sem fragmentação, mas conforme você usa o banco de dados (inserir / excluir / alterar dados) repetidamente, isso pode causar fragmentação.
Além da fragmentação do banco de dados, seu banco de dados também pode enfrentar outros problemas vitais, como corrupção de banco de dados. Isso pode levar à perda de dados e danos ao site. Se você está fazendo negócios com seu site, pode ser um golpe fatal para você.
