
5 verdades sobre o DeepSeek que foram mal compreendidas, reveladas pelo próprio chefe da IA

Vamos revisar novamente: Xiaohong depende de apoio e o grande vermelho depende da vida.
DeepSeek se tornou popular durante o Festival da Primavera e, naturalmente, haverá mais problemas quando se tornar popular. Especialmente com as complicadas mudanças na situação no exterior, a origem chinesa do DeepSeek atraiu muitos rumores.
Tanishq Mathew Abraham, ex-diretor de pesquisa da Stability AI, deu um passo à frente ontem e apontou vários pontos muito especiais do DeepSeek como membro do setor:
1. O desempenho é na verdade tão bom quanto o o1 do OpenAI, que é um modelo de ponta que marca que o código aberto realmente alcançou o código fechado
2. Comparado com outros modelos de ponta, o DeepSeek é concluído com um custo de treinamento relativamente baixo
3. A interface fácil de usar, combinada com cadeias de pensamento visíveis em seu site e aplicativos, atrai milhões de novos usuários.
Além disso, ele escreveu uma longa postagem no blog em resposta a vários rumores populares, analisando e explicando os comentários (ultrajantes) em torno do DeepSeek.
A seguir está uma postagem de blog com conteúdo editado:
Em 20 de janeiro de 2025, uma empresa chinesa de IA chamada DeepSeek abriu o código-fonte e lançou seu modelo de inferência R1. Dado que a DeepSeek é uma empresa chinesa, os Estados Unidos e a sua empresa AGI têm várias “preocupações de segurança nacional”. Por causa disso, **a desinformação sobre o assunto se espalhou amplamente. **
O objetivo deste artigo é refutar as muitas opiniões extremamente ruins relacionadas à IA que foram feitas sobre o DeepSeek desde seu lançamento. Ao mesmo tempo, como investigador de IA que trabalha na vanguarda da IA generativa, apresento uma perspectiva mais equilibrada.
Rumor 1: Suspeito! DeepSeek é uma empresa chinesa que apareceu de repente
Completamente errado, em janeiro de 2025, quase todos os pesquisadores de IA generativa terão ouvido falar do DeepSeek. DeepSeek até lançou uma prévia do R1 meses antes de seu lançamento completo!
Qualquer pessoa que espalhe esse boato provavelmente não funciona com inteligência artificial – é ridículo e extremamente vaidoso pensar que você sabe tudo o que há para saber se não estiver envolvido na área.
O primeiro modelo de código aberto do DeepSeek, DeepSeek-Coder, foi lançado em novembro de 2023. Na época, eram os LLMs de código líderes do setor (Nota do editor: Modelos de linguagem focados na compreensão e geração de código). Como mostra o gráfico abaixo, o DeepSeek continuou a ser comercializado em um ano, atingindo R1: 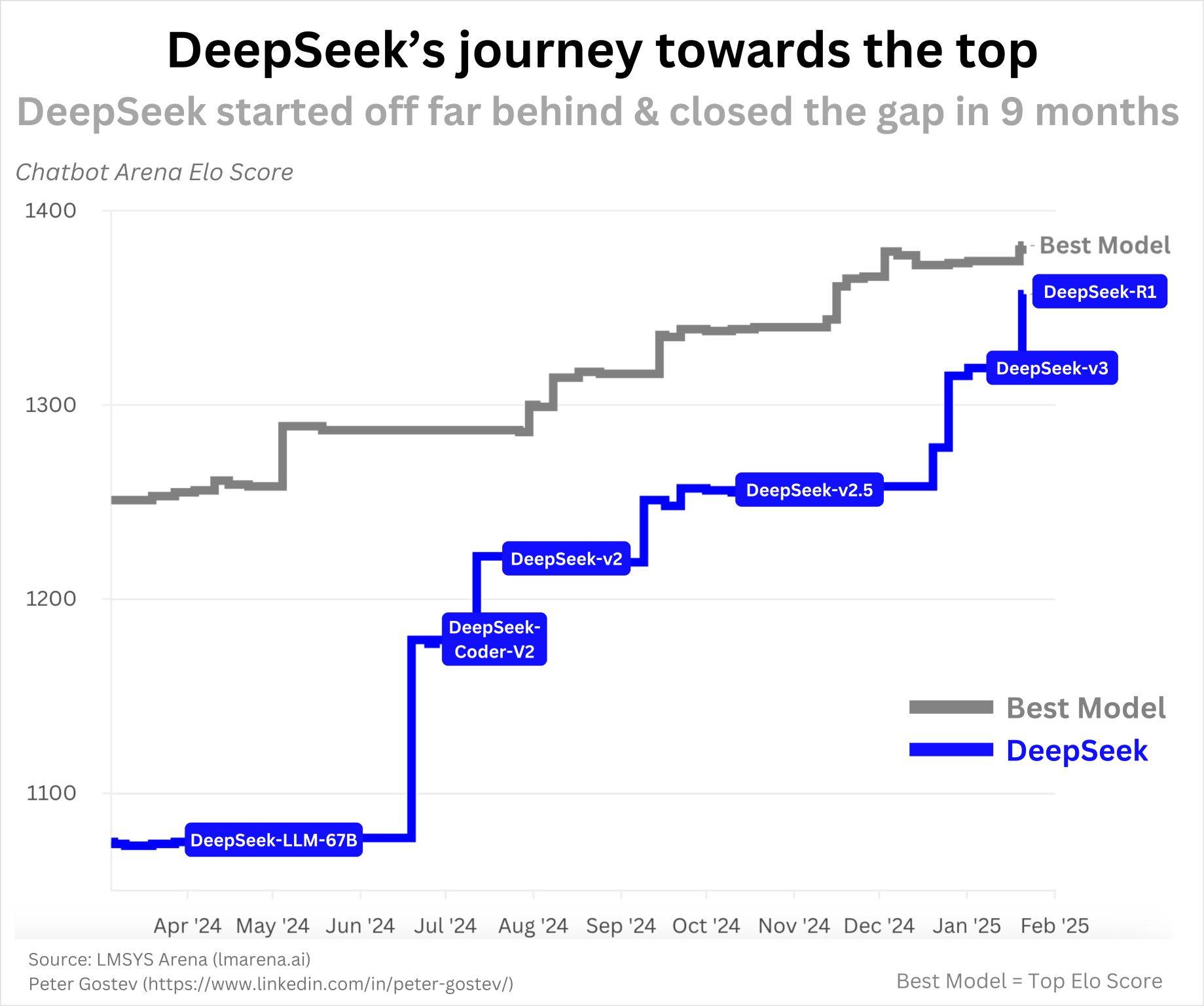
Este não foi um sucesso instantâneo e não há nada de suspeito no ritmo do seu progresso. Com a IA avançando tão rapidamente e eles têm uma equipe obviamente eficiente, fazer tanto progresso em um ano me parece muito razoável.
Se você quiser saber quais empresas estão fora dos olhos do público, mas são altamente promissoras no campo da IA, recomendo prestar atenção a Qwen (Alibaba), YI (Zero Yiwu), Mistral, Cohere, AI2. É importante notar que eles não lançam modelos SOTA de forma tão consistente quanto o DeepSeek, mas ambos têm potencial para lançar modelos excelentes, como demonstraram no passado.
Rumor 2: Mentindo! Este modelo não custa US$ 6 milhões
Esta é uma questão interessante. Tais rumores sugerem que a DeepSeek queria evitar admitir que tinha acordos ilegais nos bastidores para obter recursos computacionais aos quais não deveriam ter acesso (devido aos controles de exportação), mentindo assim sobre a verdade sobre o custo do treinamento do modelo.
Primeiro, o valor de US$ 6 milhões merece uma boa olhada. É mencionado no artigo DeepSeek-V3, lançado um mês antes do artigo DeepSeek-R1:

DeepSeek-V3 é o modelo básico do DeepSeek-R1, o que significa que DeepSeek-R1 é DeepSeek-V3 mais algum treinamento adicional de aprendizagem por reforço. Portanto, até certo ponto, o custo já é impreciso porque o custo adicional do treinamento de aprendizagem por reforço não é contabilizado. Mas isso provavelmente custaria apenas algumas centenas de milhares de dólares.
Ok, então os US$ 5,5 milhões mencionados no artigo do DeepSeek-V3 estão incorretos? Numerosas análises baseadas no custo da GPU, no tamanho do conjunto de dados e no tamanho do modelo produziram estimativas semelhantes. Observe que, embora o DeepSeek V3/R1 seja um modelo de parâmetro 671B, é um modelo de mistura especialista, o que significa que qualquer chamada de função/passagem direta do modelo usa apenas parâmetros de ~37B, que é o valor usado para calcular o custo de treinamento.
No entanto, o custo do DeepSeek é uma estimativa do custo dessas GPUs com base nos preços atuais de mercado. Na verdade, não sabemos o custo de seu cluster de GPU 2048 H800 (nota: não H100s, este é um equívoco e confusão comum!). Normalmente, clusters de GPU contíguos custam menos quando adquiridos em massa, portanto podem até ser mais baratos.
Mas aqui está o problema: no final, é o custo de operação. Antes que isso fosse bem-sucedido, muitos experimentos e ablações provavelmente foram realizados em pequena escala, o que exigiria custos consideráveis, mas estes não são relatados aqui.
Além disso, pode haver muitos outros custos, como o salário do pesquisador. SemiAnalysis relata que há rumores de que os salários dos pesquisadores da DeepSeek giram em torno de US$ 1 milhão. Isto equivale aos altos níveis salariais dos laboratórios de ponta da AGI, como OpenAI ou Anthropic.
Normalmente, ao relatar e comparar custos de treinamento para diferentes modelos, o custo final da execução do treinamento é a maior preocupação. Mas devido à fraca retórica e à propagação de desinformação, as pessoas têm argumentado que os custos adicionais põem em causa a natureza eficiente e de baixo custo das operações da DeepSeek. Isto é extremamente injusto. Os custos são significativos, tanto do ponto de vista da ablação/experimental quanto do ponto de vista da remuneração do pesquisador em outros laboratórios de ponta da AGI, mas muitas vezes não são mencionados em discussões como esta!
Rumor 3: Tão barato? Todas as empresas AGI dos EUA estão desperdiçando dinheiro, pessimista para a Nvidia
Acho que essa é outra ideia bastante estúpida. DeepSeek é de fato mais eficiente no treinamento do que muitos outros LLMs. Sim, é muito possível que muitos dos laboratórios de ponta da América sejam computacionalmente ineficientes. No entanto, isso não significa necessariamente que ter mais recursos computacionais seja algo ruim.
Para ser honesto, sempre que ouço opiniões como essa, fica claro para mim que eles não entendem as leis de escala, nem a mentalidade do CEO da AGI (e de qualquer pessoa considerada um especialista em IA). Deixe-me oferecer algumas reflexões sobre este tópico.
As leis de escala mostram que, à medida que continuarmos a colocar mais poder computacional no modelo, obteremos melhor desempenho. É claro que os métodos e aspectos exatos do dimensionamento da IA mudaram ao longo do tempo: inicialmente o tamanho do modelo, depois o tamanho do conjunto de dados e agora o cálculo do tempo de inferência e os dados sintéticos.
A tendência geral de mais poder computacional igualando melhor desempenho parece continuar desde o Transformer original em 2017.
Um modelo mais eficiente significa que você obtém melhor desempenho para um determinado orçamento de computação, mas mais recursos de computação são ainda melhores. Um modelo mais eficiente significa que você pode fazer mais com menos recursos computacionais, mas fazer mais com mais recursos computacionais!
Você pode ter suas próprias opiniões sobre as leis de escala. Você pode pensar que um platô está chegando. Você pode pensar que o desempenho passado não é uma indicação de resultados futuros, como se costuma dizer no mundo financeiro.
Mas e se todas as maiores empresas de AGI apostarem que as leis de escalonamento durarão o suficiente para permitir a AGI e a ASI? Sendo esta a sua firme convicção, o único curso de ação lógico é adquirir mais poder computacional.
Agora você pode estar pensando “As GPUs da NVIDIA ficarão obsoletas em breve, veja AMD, Cerebras, Graphcore, TPUs, Trainium, etc.” Existem milhões de produtos de hardware voltados para IA, todos tentando competir com a NVIDIA. Um deles pode vencer no futuro. Nesse caso, talvez essas empresas de AGI recorram a eles – mas isso não tem absolutamente nada a ver com o sucesso do DeepSeek.
Pessoalmente, não creio que haja fortes evidências de que outras empresas desafiarão o domínio da NVIDIA em chips de aceleração de IA, dado o atual domínio de mercado da NVIDIA e o nível contínuo de inovação.
No geral, não vejo por que DeepSeek significa que você deveria estar pessimista em relação à NVIDIA. Você pode ter outros motivos para ser pessimista em relação à NVIDIA, e esses motivos podem ser muito válidos e válidos, mas DeepSeek não me parece o certo.
Rumor 4: É apenas uma imitação! DeepSeek não fez nenhuma inovação significativa
erro. **Houve muitas inovações no design de modelos de linguagem e nos métodos de treinamento, algumas mais importantes que outras**. Aqui estão alguns (não uma lista completa, você pode ler os artigos DeepSeek-V3 e DeepSeek-R1 para obter mais detalhes):
Atenção latente de múltiplas cabeças (MLA) – LLMs geralmente se referem a transformadores que utilizam o chamado mecanismo de atenção de múltiplas cabeças (MHA). A equipe DeepSeek desenvolveu uma variante do mecanismo MHA que é mais eficiente em termos de memória e oferece melhor desempenho.
GRPO e recompensas verificáveis – os profissionais de IA têm tentado replicar o1 desde seu lançamento. Como o OpenAI tem sido bastante reservado sobre como funciona, as pessoas tiveram que explorar uma variedade de métodos diferentes para obter resultados semelhantes aos do O1. Houve várias tentativas, como a pesquisa em árvore de Monte Carlo (método utilizado pelo Google DeepMind para vencer no Go), que se revelou menos promissora do que inicialmente esperado.
DeepSeek demonstra que um pipeline de aprendizagem por reforço (RL) muito simples pode realmente alcançar resultados semelhantes a o1. Além disso, eles desenvolveram sua própria variante do algoritmo PPO RL comum, denominado GRPO, que é mais eficiente e tem melhor desempenho. Acho que muitas pessoas na comunidade de IA estão se perguntando: por que não tentamos isso antes?
DualPipe – Há muitos aspectos de eficiência a serem considerados ao treinar um modelo de IA em várias GPUs. Você precisa descobrir como o modelo e o conjunto de dados são distribuídos por todas as GPUs, como os dados fluem pelas GPUs, etc. Você também precisa reduzir qualquer transferência de dados entre GPUs, pois é muito lenta e é melhor tratada em cada GPU separada, se possível. Independentemente disso, há muitas maneiras de configurar esse tipo de treinamento multi-GPU, e a equipe DeepSeek projetou uma solução nova, mais eficiente e mais rápida chamada DualPipe.
Temos muita sorte de a DeepSeek ter aberto completamente o código dessas inovações e escrito introduções detalhadas, ao contrário da empresa americana AGI. Agora, todos podem se beneficiar dessas formas inovadoras de melhorar o treinamento de seu próprio modelo de IA.
Rumor 5: DeepSeek está “extraindo” conhecimento do ChatGPT
David Sacks (gigante de IA e criptografia do governo dos EUA) e OpenAI afirmam que DeepSeek “drenou” o conhecimento do ChatGPT usando uma técnica chamada destilação.
Em primeiro lugar, a palavra "destilação" é usada aqui de forma muito estranha. Normalmente, a destilação refere-se ao treinamento nas probabilidades completas (logits) de todas as próximas palavras possíveis (tokens), mas essas informações não podem nem mesmo ser expostas por meio do ChatGPT.
Mas tudo bem, digamos que estamos falando de treinamento com texto gerado pelo ChatGPT, embora esse não seja o uso típico do termo.
A OpenAI e seus funcionários afirmam que o próprio DeepSeek usa ChatGPT para gerar texto e treiná-lo. Eles não forneceram nenhuma evidência, mas se isso for verdade, então o DeepSeek violou claramente os termos de serviço do ChatGPT. Acho que as ramificações legais para uma empresa chinesa não são claras, mas não sei muito sobre isso.
Observe que isso ocorrerá apenas se o próprio DeepSeek gerar os dados usados para treinamento. Se o DeepSeek usa dados gerados pelo ChatGPT de outras fontes (atualmente existem muitos conjuntos de dados públicos), meu entendimento é que essa “destilação” ou treinamento de dados sintéticos não é proibido pelos TOS.
No entanto, na minha opinião, isso não diminui as conquistas do DeepSeek. O que mais me impressionou como pesquisador do que o aspecto de eficiência do DeepSeek foi a replicação do o1. Duvido muito que a “destilação” do ChatGPT seja de alguma ajuda. Essa dúvida decorre inteiramente do fato de que o processo de pensamento do CoT de o1 nunca foi tornado público, então como o DeepSeek pode aprendê-lo?
Além disso, muitos LLMs são de fato treinados em ChatGPT (bem como em outros LLMs), e naturalmente haverá texto de IA em qualquer conteúdo da Internet recém-copiado.
No geral, acreditar que o modelo do DeepSeek tem um bom desempenho simplesmente porque simplesmente destila a perspectiva do ChatGPT é ignorar a realidade da engenharia, eficiência e inovação arquitetônica do DeepSeek.
Deveríamos estar preocupados com a hegemonia da China na inteligência artificial?
Talvez um pouco? Falando francamente, em comparação com dois meses atrás, a competição de IA sino-americana não mudou muito em sua essência. Pelo contrário, a reacção do mundo exterior é bastante feroz, o que pode de facto afectar o panorama geral da IA através de mudanças no financiamento, supervisão, etc.
Os chineses sempre foram competitivos em IA, e o DeepSeek agora os torna impossíveis de ignorar.
O argumento típico sobre o código aberto é que, como a China está atrasada, não deveríamos partilhar abertamente a nossa tecnologia para deixá-la recuperar o atraso. Mas, obviamente, a China alcançou, na verdade, eles recuperaram o atraso há muito tempo, estão na verdade liderando o caminho no código aberto, então não está claro se um maior reforço da nossa tecnologia irá realmente ajudar tanto.
Observe que empresas como OpenAI, Anthropic e Google DeepMind definitivamente têm modelos melhores que DeepSeek R1. Por exemplo, os resultados de benchmark do modelo o3 da OpenAI são bastante impressionantes e podem já ter um modelo de acompanhamento em desenvolvimento.
Com base nesta base, e com investimentos adicionais significativos, como o Projeto Stargate e a próxima rodada de financiamento da OpenAI, a OpenAI e outros laboratórios de ponta dos EUA terão amplo poder de computação para manter sua posição de liderança.
É claro que a China investirá fundos adicionais significativos no desenvolvimento da IA. Então, no geral, a competição está esquentando! Mas acho que o caminho para os laboratórios de ponta da AGI dos EUA permanecerem à frente ainda é bastante promissor.
para concluir
Por um lado, algumas pessoas de IA, especialmente as da OpenAI, estão tentando minimizar o DeepSeek. Por outro lado, alguns críticos e autoproclamados especialistas reagiram exageradamente ao DeepSeek.
Deve-se ressaltar que OpenAI/Anthropic/Meta/Google/xAI/NVIDIA, etc. Não, DeepSeek (provavelmente) não mentiu sobre o que fez. Independentemente disso, é preciso admitir: o DeepSeek merece reconhecimento, o R1 é um modelo impressionante.
https://www.tanishq.ai/blog/posts/deepseek-delusions.html
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
