
O maior escândalo no círculo de IA deste ano foi exposto! Llama 4 foi denunciado como trapaceiro no treinamento, falhou no teste real e a equipe principal renunciou com raiva

Ontem, Meta Llama 4 foi lançado do nada.
Os parâmetros no papel são muito altos. Diz-se que é um modelo MOE multimodal nativo, superando o DeepSeek V3 e uma besta de 2 trilhões de parâmetros. Até o CEO da Meta, Zuckerberg, postou um vídeo agitando a bandeira e gritando para dar as boas-vindas ao “Llama 4th”.
Os aplausos duraram pouco. Quando os internautas começaram a testar, eles receberam críticas quase esmagadoramente negativas. Pode ser considerado o maior evento de “rollover” na indústria de IA este ano.
Na comunidade r/LocalLLaMA (que pode ser entendida como "post bar" do Llama) dedicada à implantação local de grandes modelos de linguagem, um post intitulado "Sinto-me incrivelmente decepcionado com o Llama 4" rapidamente ganhou muita atenção e ressonância.
Existem até fãs leais do Llama que quebraram a defesa e disseram sem rodeios que é hora de renomear "LocalLLaMA" para "LocalGemma". Zombar do lançamento do Llama 4 é mais como uma piada tardia do Dia da Mentira.

O teste real mostrou que os produtos não estavam corretos e foi revelado que o Llama 4 era louco por “preencher perguntas” antes do lançamento.
Nesta postagem original no Reddit, o internauta Karminski desaconselha fortemente o uso do Llama 4 para codificação.
Ele disse que o Llama-4-Maverick – um modelo com um parâmetro total de 402B – mal consegue se igualar ao Qwen-QwQ-32B em termos de capacidades de codificação. O desempenho do Llama-4-Scout (modelo com parâmetros totais 109B) é aproximadamente semelhante ao Grok-2 ou Ernie 4.5.
Na verdade, de acordo com os últimos resultados de benchmark de codificação poliglota do Aider, o Llama 4 Maverick obteve apenas 16%.
Este benchmark foi projetado para avaliar o desempenho de grandes modelos de linguagem (LLM) em tarefas de programação multilíngue, cobrindo seis linguagens de programação convencionais C++, Go, Java, JavaScript, Python e Rust.
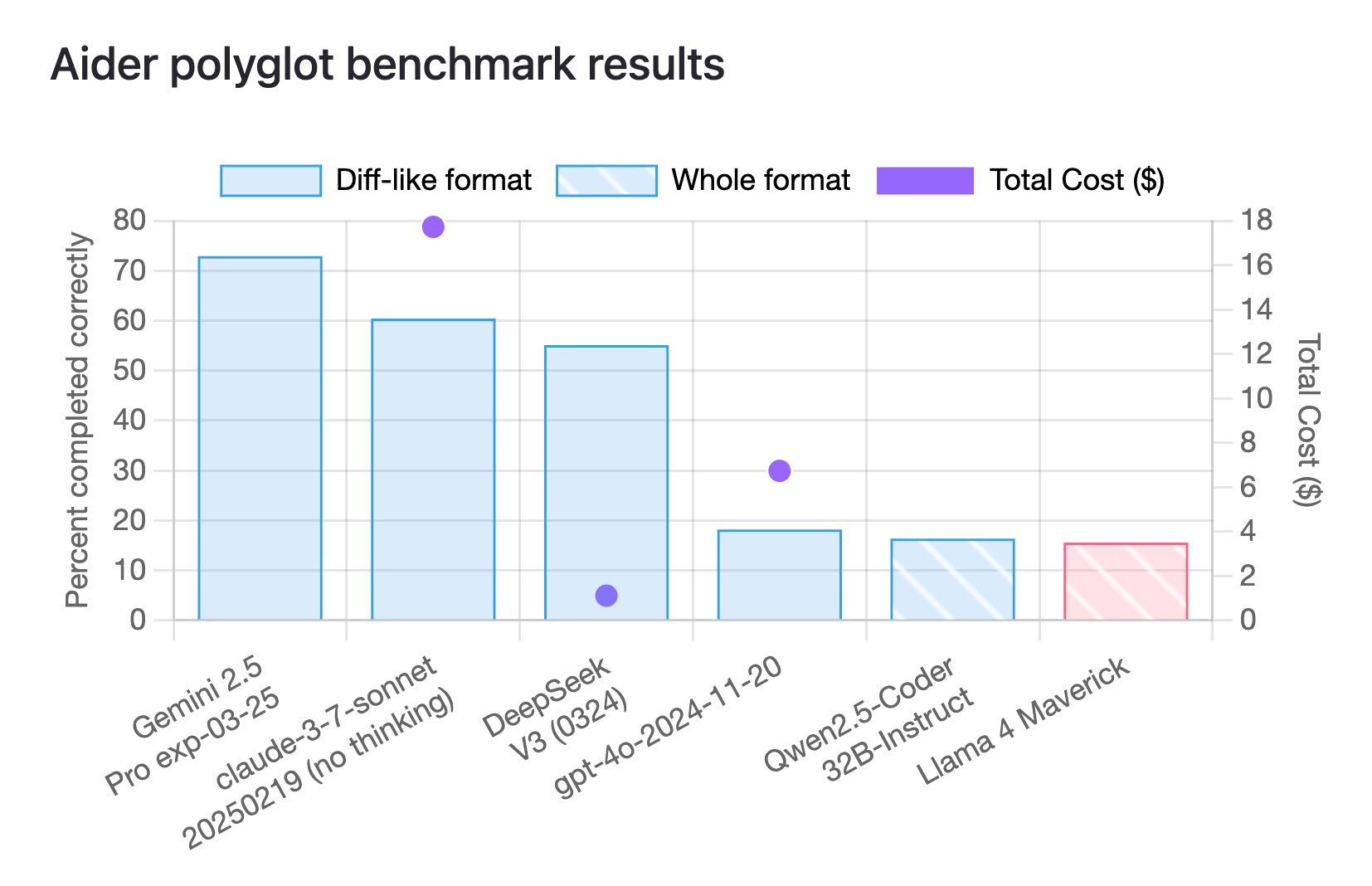
E essa pontuação também está no nível mais baixo entre muitos modelos.
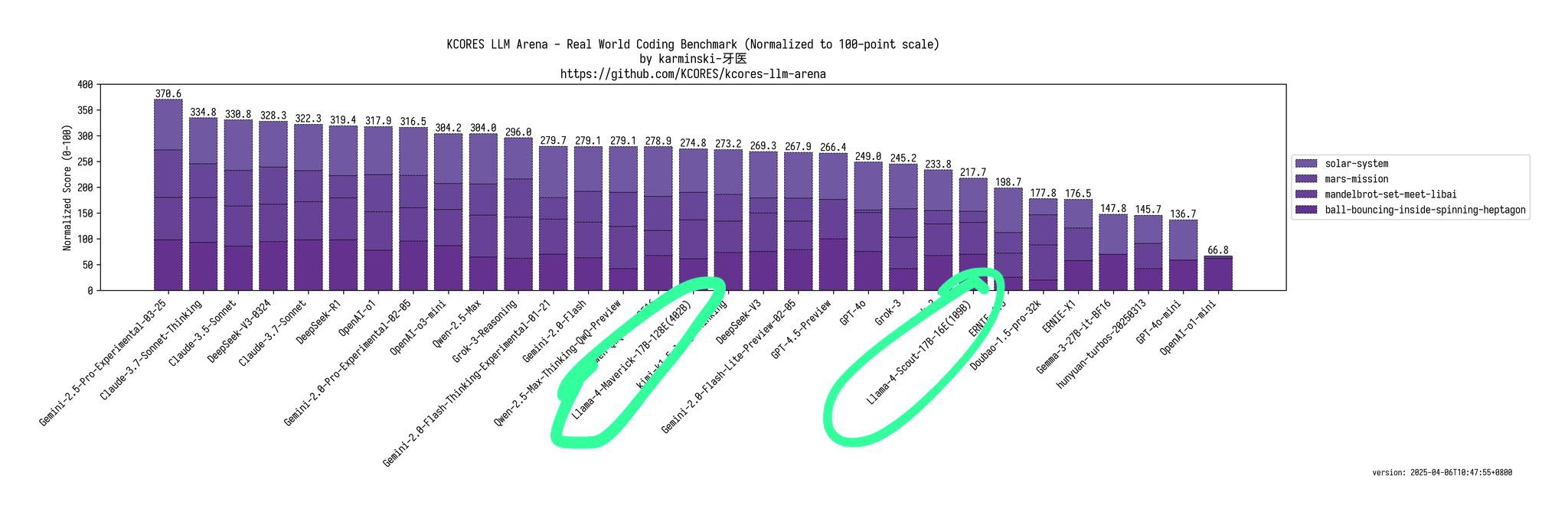
O blogueiro @deedydas também expressou sua decepção com o Llama 4, chamando-o de “um modelo de programação terrível”.
Ele destacou que Scout (109B) e Maverick (402B) têm desempenho muito pior que 4o, Gemini Flash, Grok 3, DeepSeek V3 e Sonnet 3.5/7 no teste de benchmark Kscores para tarefas de programação.
Outro internauta, Flavio Adamo, pediu ao Llama 4 Maverick e ao GPT-4o que gerassem uma animação de uma pequena bola quicando em um polígono giratório, e a bola deve seguir a influência da gravidade e do atrito durante o processo de salto.
Os resultados mostram que a forma poligonal gerada pelo Llama 4 Maverick carece de aberturas e o movimento da bola também viola as leis da física. Em comparação, o desempenho da nova versão do GPT-4o é significativamente melhor, e o desempenho do Gemini 2.5 Pro é o rei.

Olhando para trás, em janeiro deste ano, Zuckerberg também afirmou que a IA alcançaria o nível de programação de um engenheiro de software intermediário. O atual fraco desempenho do Llama 4 é de fato um tapa na cara um pouco rápido.
Além disso, o comprimento do contexto do Llama 4 Scout chega a 10 milhões de tokens. Esse comprimento de contexto extremamente longo permite que o Llama 4 Scout processe e analise conteúdos de texto extremamente longos, como livros inteiros, grandes bibliotecas de códigos ou arquivos multimídia.
Os funcionários da Meta até mostraram os resultados do teste de “encontrar uma agulha no palheiro” para provar suas capacidades.
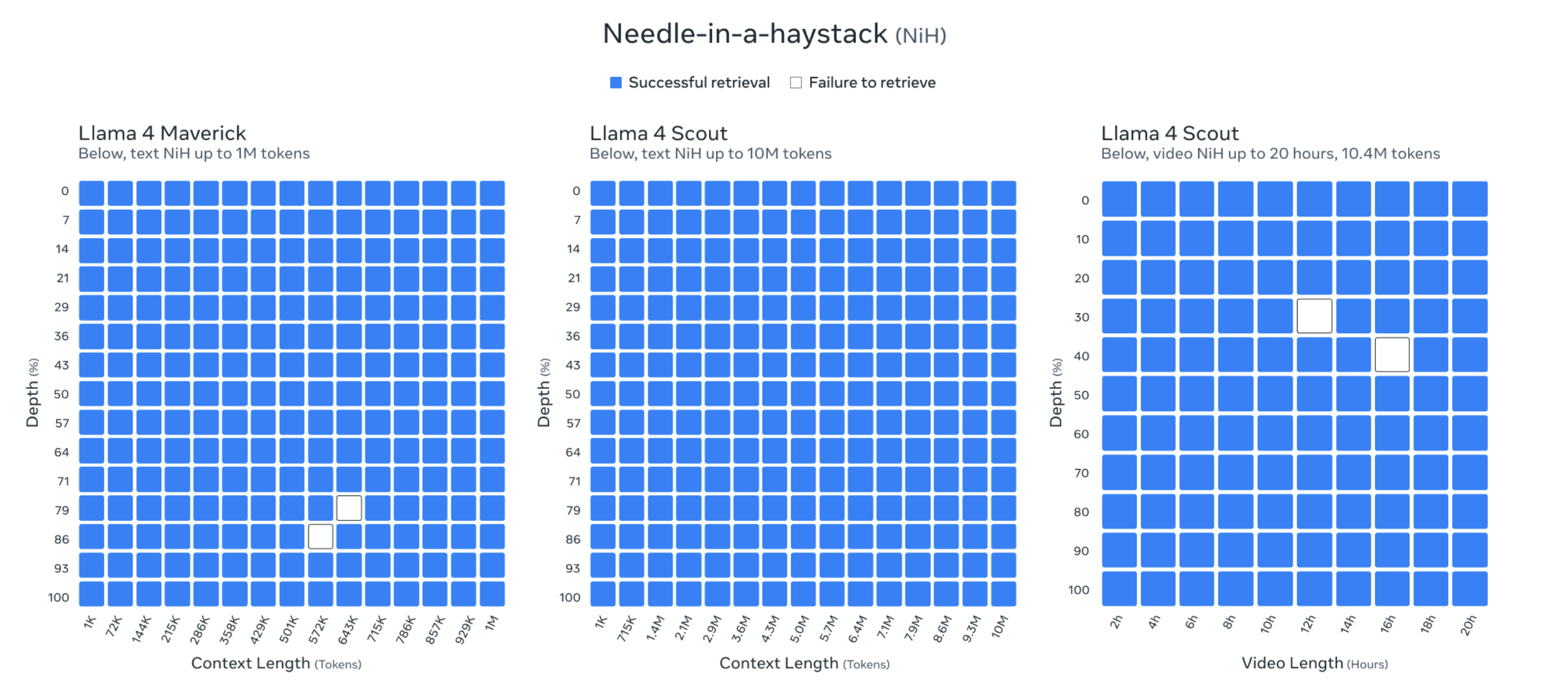
No entanto, de acordo com os últimos resultados do Fiction.LiveBench, o efeito do modelo Llama 4 também é medíocre e inútil, e o efeito geral não é tão bom quanto o Gemini 2.0 Flash, enquanto o Gemini 2.5 Pro ainda é o merecido rei do texto longo.
+1 para Oita no Google.
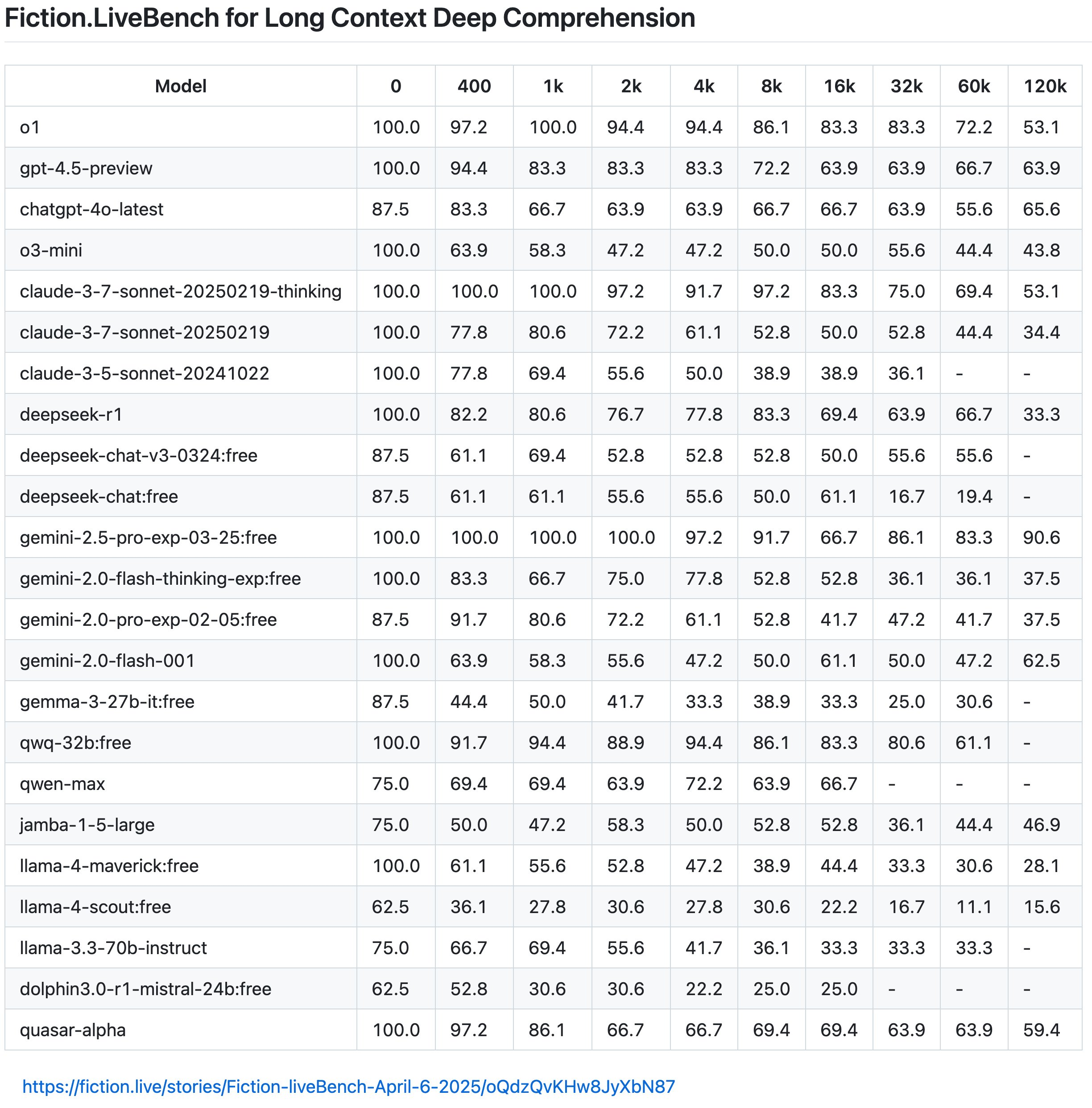
O internauta Karminski apontou ainda que o Llama 4 caiu abaixo de 60% quando a taxa de recuperação do contexto é de 1K (aproximadamente entendida como a taxa correta de resposta a perguntas), e mesmo o Llama-4-Scout tem apenas 22% quando excede 16K.
Ele também deu um exemplo vívido: “O comprimento do texto de “Harry Potter e a Pedra Filosofal” é de cerca de 16K.
Isso significa que se você inserir o livro inteiro no modelo e depois perguntar "Harry morava no quarto ou no depósito embaixo da escada quando era criança?", Llama-4-Scout só acertará a resposta 22% das vezes (entendimento aproximado, o mecanismo de recuperação real é mais complicado). E esse resultado é naturalmente muito inferior ao nível médio do modelo principal.
Não apenas o modelo em si está ligeiramente esticado, mas o halo do Llama 4 como “líder de código aberto” também está desaparecendo gradualmente.
Meta abre os pesos do Llama 4, mas mesmo usando quantização, ele não pode rodar em GPUs de consumo. Diz-se que funciona em uma única placa, mas na verdade se refere ao H100. O limite alto é bastante hostil para os desenvolvedores.
Além do mais, a nova licença do Llama 4 tem várias restrições, a mais criticada delas é que empresas com mais de 700 milhões de usuários ativos mensais devem solicitar uma licença especial da Meta, que a Meta pode decidir a seu próprio critério se aprova ou rejeita.

Espere, não é isso que diziam os parâmetros do papel anunciados pela Meta ontem. Ora, um dia depois, a direção do vento mudou completamente.
No ranking Arena de modelos grandes, o Llama 4 Maverick ficou em segundo lugar na lista geral, tornando-se o quarto modelo a ultrapassar 1.400 pontos. Ele liderou a lista entre os modelos de código aberto, superando o DeepSeek V3.
Diante do fato de que o desempenho medido “não estava certo”, internautas atentos rapidamente perceberam algo suspeito. Maverick, que alcançou pontuações altas na LM Arena, na verdade usou uma “versão experimental de bate-papo”.

Isso ainda não acabou. A postagem de notícias de hoje sobre a comunidade One Acre Three-quarter Land parece ter revelado algumas histórias internas. Foi relatado que após treinamento repetido, o Llama 4 não conseguiu obter o SOTA de código aberto e estava até longe disso.
O prazo definido internamente pela Meta Company para lançamento é final de abril.
Portanto, a liderança da empresa sugeriu misturar os conjuntos de testes de vários benchmarks no processo pós-treinamento, na esperança de alcançar a fertilização cruzada em vários indicadores. Obtenha um resultado que "pareça bom".
A mistura de conjuntos de testes de vários benchmarks no processo de pós-treinamento mencionado aqui significa que na fase de pós-treinamento do modelo, ao misturar conjuntos de dados de diferentes benchmarks, o modelo pode aprender em uma variedade de tarefas e cenários, melhorando assim sua capacidade de generalização.
Para usar uma analogia simples, isso é como colar em uma prova. As questões do teste deveriam ser selecionadas aleatoriamente de um banco de questões confidenciais (conjunto de testes de referência), e ninguém sabia disso antes do teste. Mas se alguém der uma olhada nas questões com antecedência e praticá-las repetidamente (o equivalente a misturar o conjunto de testes com o treinamento), com certeza se sairá bem no exame.
O autor da postagem explicou ainda que após o lançamento do Llama 4, os resultados reais dos testes foram criticados pelos internautas do X e do Reddit. Como alguém que atualmente trabalha na academia, ele afirmou que realmente não poderia aceitar a abordagem da Meta. Ele apresentou seu pedido de demissão e solicitou explicitamente que seu nome fosse retirado do Relatório Técnico do Llama 4.
Ele também disse que o vice-presidente de IA da Meta também renunciou por esse motivo. Há alguns dias, foi relatado que Joelle Pineau, chefe de pesquisa da Meta AI, anunciou que deixaria seu cargo em 30 de maio.

No entanto, podem ser necessárias mais provas quanto à veracidade desta alegada acusação de “fraude de lista”. Um funcionário da Meta chamado LichengYu também respondeu com seu nome verdadeiro na área de comentários:
“Nos últimos dois dias, ouvi humildemente o feedback de todas as partes (como codificação, escrita criativa e outros defeitos que precisam ser melhorados) e espero melhorar na próxima versão. No entanto, nunca ajustamos demais o conjunto de teste para melhorar pontos.

Informações públicas mostram que Licheng Yu se formou na Universidade Jiao Tong de Xangai, recebeu mestrado duplo do Instituto de Tecnologia da Geórgia e da Universidade Jiao Tong de Xangai em 2014 e recebeu um doutorado em ciência da computação pela Universidade da Carolina do Norte em Chapel Hill em maio de 2019.
Seus campos de pesquisa concentram-se em visão computacional e processamento de linguagem natural, e muitos artigos foram aceitos em conferências importantes, como CVPR, ICLR, ECCV e KDD.
Licheng Yu tem experiência profissional em grandes empresas como Microsoft e Adobe. Atualmente, ele atua como gerente cientista pesquisador da Meta (2023.06 até o presente). Participou do lançamento do modelo multimodal Llama3.2 (11B+90B) e liderou a fase de aprendizagem por reforço de texto + imagem de 17Bx128 e 17Bx16 no projeto Llama 4.
É difícil dizer se é verdade ou não, e talvez isso possa manter as balas voando por mais algum tempo.
O “trono” dos grandes modelos de código aberto não pode ser tomado pela força bruta
Nesta mesma época do ano passado, Meta foi aclamada como a escolhida na indústria de IA.
É claro que, depois de tirar sua simples camiseta cinza, jeans e moletom com capuz, Zuckerberg também começou a usar frequentemente roupas de marca com grandes logotipos, pendurando grandes e ásperas correntes de ouro no pescoço e até exibindo com confiança seus resultados de condicionamento físico em público.
Zuckerberg, que não tem interesse em beber, tenta se aproximar do público mostrando um lado mais “real” e “pé no chão”. Isso não apenas faz com que o Meta pareça mais amigável às pessoas, mas também o torna o porta-estandarte do código aberto em relação ao modelo de código fechado da OpenAI, com um impulso incomparável.

Ao mesmo tempo, a forte força do Meta fornece um apoio sólido para a transformação. É relatado que a Meta planeja investir até US$ 65 bilhões em 2025 para expandir sua infraestrutura de IA, o que representa uma grande quantia na indústria. Até o final de 2025, a Meta planeja ter mais de 1,3 milhão de GPUs.
Em segundo lugar, o Meta possui dados abundantes de plataformas sociais, o que lhe proporciona vantagens únicas em pesquisa e desenvolvimento de IA.
Como controladora de plataformas sociais de renome mundial, como Facebook, Instagram e WhatsApp, a Meta possui dados sobre as interações diárias de bilhões de usuários. Segundo as estatísticas, o número global de utilizadores ativos diários (DAU) da sua plataforma ultrapassará os 3 mil milhões em 2024. Este enorme volume de dados fornece enormes matérias-primas para a formação de modelos de IA.
Além disso, a Meta não é menos generosa em seu conjunto de talentos. O líder de seu departamento de IA é o prestigiado vencedor do Prêmio Turing, Yann LeCun. Sob sua liderança, Meta aderiu à estratégia de código aberto e lançou a série de modelos Llama.
Portanto, Meta também é muito ambicioso – não só quer consolidar sua posição no campo social, mas também espera conseguir ultrapassagens em curva no campo da IA, com o objetivo de superar concorrentes fortes como o OpenAI até o final de 2025.

Mas eu o vi construindo um Zhulou, o vi recebendo convidados e vi sua torre desabar.
Se a notícia de One Third Acre for verdadeira, pode haver "trapaça" no processo de desenvolvimento do Llama 4 em busca de resultados de testes de benchmark – ao misturar o conjunto de testes nos dados de treinamento, é mais como uma deformação operacional sob "ansiedade de tráfego de IA".
No início do ano, houve notícias de que o DeepSeek causou pânico na equipe Meta AI:
“Quando o salário de cada executivo na organização de IA generativa for superior ao custo de treinamento de todo o DeepSeek-V3, e tivermos dezenas desses executivos, como eles enfrentarão a alta administração?”
Em 2023, Meta estabeleceu quase um monopólio no campo de grandes modelos de código aberto com a série Llama, tornando-se sinônimo e referência para IA de código aberto.
No entanto, um dia para a IA e um ano para os seres humanos. Na área de comentários onde o Llama 4 encontrou "Waterloo", elogios de outros modelos de código aberto podem ser vistos em todos os lugares. Entre eles, o Google Gemma ganhou amplo reconhecimento por seu peso leve, alta eficiência e capacidades multimodais, os modelos básicos da série Qwen do Alibaba surgiram e o DeepSeek chocou toda a indústria com seu status de azarão de baixo custo e alto desempenho.
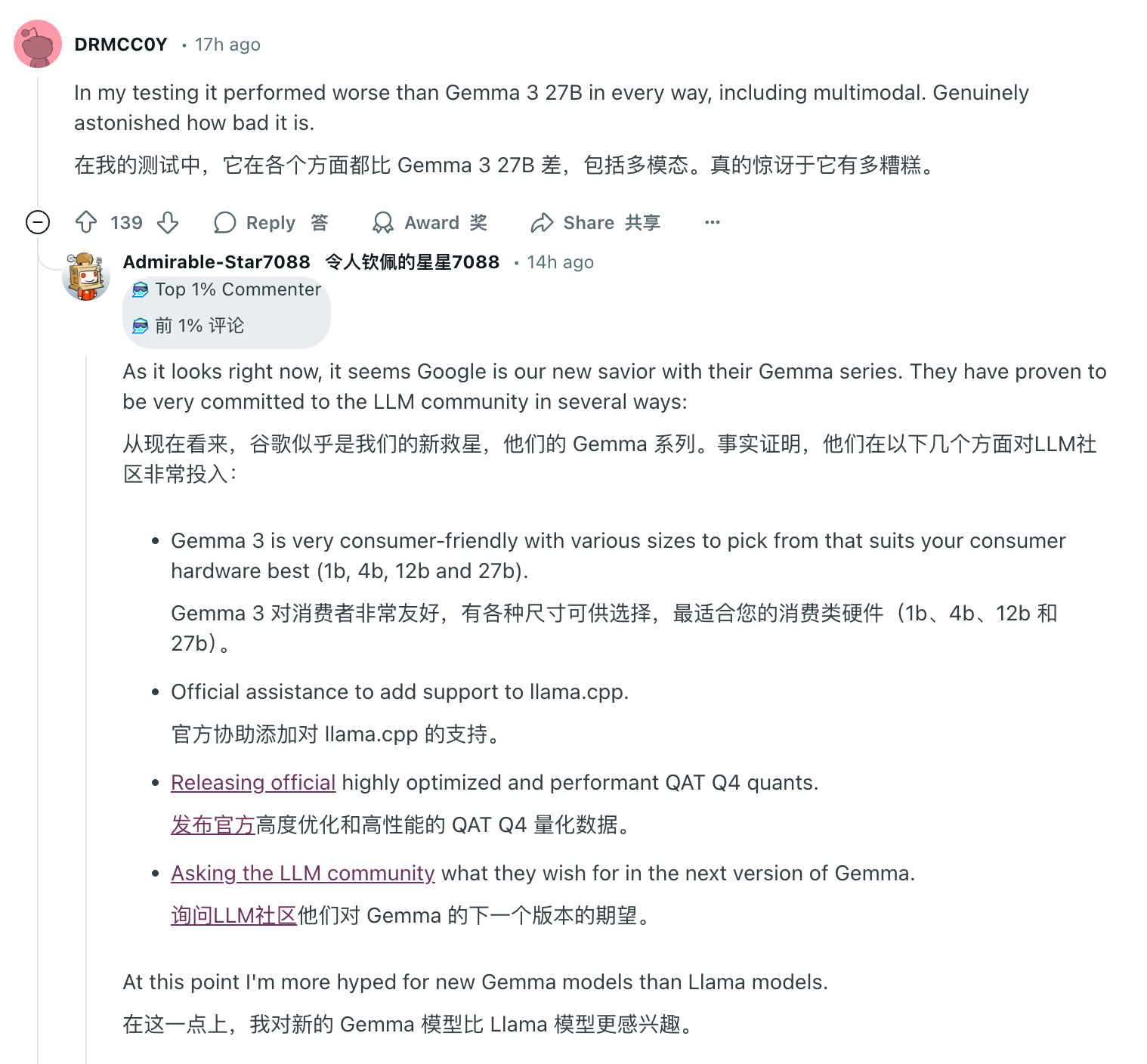
Ainda não se sabe se Meta pode ajustar sua estratégia e retornar à posição de liderança dos modelos de IA de código aberto, mas em qualquer caso, o florescimento da IA de código aberto chegou irreversivelmente.
Seguindo o princípio de que a IA é fácil de usar e qual deve ser usada, a Meta não pode culpar inteiramente os usuários. Além do mais, em termos de transparência de código aberto, em comparação com os modelos de código aberto das empresas acima mencionadas, as restrições autoimpostas do Llama 4 também significam que ele cortou um braço.
As lutas atuais do Meta também podem mostrar que, mesmo que tenha todo o poder de computação da GPU e dados massivos do mundo, as vantagens dos recursos não são mais o fator decisivo. O “trono” dos grandes modelos de código aberto não pode ser conquistado pela força bruta.
# Bem-vindo a seguir a conta pública oficial do WeChat do aifaner: aifaner (WeChat ID: ifanr). Conteúdo mais interessante será fornecido a você o mais rápido possível.
