
O futuro da OpenAI pode ter que ser “salvo” por “Harry Potter”

A lei de direitos autorais é uma espada afiada que paira sobre as cabeças das empresas de IA.
Quando o New York Times anunciou oficialmente seu processo contra a OpenAI e a Microsoft por violação, o fio dessa espada foi revelado novamente, o que parecia indicar que 2024 será outro ano marcante.
Afinal, embora o New York Times não tenha proposto um montante específico de compensação, exigiu que as duas empresas destruíssem os chatbots e os dados de formação envolvidos na utilização de materiais relacionados com o New York Times.

Sempre foi algo “natural” acumular mais dados para modelos grandes e treinar IA mais “inteligente”. No entanto, ainda é muito difícil “apagar” dados específicos que foram integrados em grandes modelos de cálculo.
Há uma boa analogia: tentar “apagar” dados específicos de um modelo grande é como tentar remover ingredientes como açúcar ou manteiga de um bolo pronto.
Se ganharem o caso, os investigadores não conseguirão excluir os dados do New York Times dos seus modelos existentes, o que significa que terão de destruir o bolo inteiro.
Quem poderia imaginar que Harry Potter poderia ajudar os gigantes da IA a sair de seu estado passivo e até mesmo participar do desenvolvimento de ponta da tecnologia de IA em uma escala mais ampla.

Não é fácil “esquecer tudo”
Obliviar! (Tudo está esquecido)
No mundo de "Harry Potter", a fim de proteger o mundo mágico, os bruxos costumam lançar feitiços de amnésia em trouxas para apagar memórias específicas depois que eles acidentalmente entram em contato ou testemunham animais mágicos ou itens mágicos.

Assim como os magos, os pesquisadores de IA também estão explorando “feitiços de esquecimento” que podem ser usados em modelos grandes.
Pesquisadores da Universidade de Washington, da Universidade da Califórnia, Berkeley, e do Instituto Allen de Inteligência Artificial desenvolveram um grande modelo de linguagem chamado "Silo" com o objetivo de criar um grande modelo que possa remover dados específicos para reduzir riscos legais.
Os investigadores dividiram os dados de formação em duas partes: dados de baixo risco de infração e dados de alto risco.
A equipe primeiro treinou um modelo usando dados de baixo risco, como livros com direitos autorais expirados e documentos governamentais.
Com base nisso, quando o modelo está inferindo, ele também pode ler uma biblioteca contendo dados de alto risco, que contém diversas informações extraídas da rede e livros publicados. A biblioteca é flexível, portanto os pesquisadores podem adicionar ou remover dados específicos da biblioteca a qualquer momento, caso surja uma disputa de direitos autorais.
A pesquisa mostra que o desempenho do modelo cai significativamente se treinado apenas com dados de baixo risco.
A fim de estudar ainda mais o impacto de textos específicos no modelo grande, os pesquisadores usaram os romances de “Harry Potter” para treinar e testar ainda mais o modelo.
Eles criaram dois conjuntos de dados: um conjunto incluía todos os livros publicados, exceto o primeiro "Harry Potter", e o segundo conjunto incluía todos os livros publicados, excluindo 7 livros de "Harry Potter". Em seguida, use esses dois conjuntos de dados para treinar o modelo.
Em seguida, repetiram o teste, mudando cada vez os dados apresentados pelo primeiro grupo para o segundo, terceiro e terceiro romances de Harry Potter, e assim por diante.
Quando excluímos os romances de Harry Potter do conjunto de dados, a perplexidade do grande modelo torna-se pior.
Isso significa que se os romances de “Harry Potter” forem eliminados, o desempenho do modelo grande piorará.

▲As consequências de derrubar a Maldição do Esquecimento
Embora o teste de Silo ajude os pesquisadores a compreender a importância do treinamento da qualidade dos dados para o desempenho de grandes modelos, essa abordagem de “eliminação” não é “esquecer” no sentido estrito, mas mais como “reduzir a exposição acessível” de conteúdo específico”.
Em outubro deste ano, pesquisadores da Microsoft tentaram um método mais próximo do “esquecimento”. Coincidentemente, eles também optaram por usar os romances de Harry Potter para testes:
Acreditamos que isso ajudará a comunidade de pesquisa a testar se nossos modelos estão realmente “esquecendo” conteúdo relevante.
Quase qualquer um pode pensar em algumas palavras para testar se o modelo entende Harry Potter. Mesmo quem nunca leu o romance tem uma certa compreensão da trama e dos personagens.
No artigo “Quem é Harry Potter?”, dois pesquisadores usaram como base o modelo de código aberto Llama2-7b da Meta e tentaram fazer com que ele “esquecesse” todo o conteúdo relacionado aos romances de “Harry Potter”.
De acordo com relatórios anteriores, os dados de treinamento do Llama2-7b também incluem o famoso grupo de dados "book3", que coleta livros protegidos por direitos autorais, incluindo "Harry Potter".
Para fazer um modelo grande “esquecer tudo”, os pesquisadores não apenas agitam uma varinha mágica e dizem um feitiço, mas precisam seguir três etapas:
- Construa um modelo aprimorado para que o conteúdo seja esquecido, ou seja, um modelo super conhecedor de “Harry Potter”, e conte com ele para descobrir quais elementos são mais relevantes para “Harry Potter”.
Você pode pensar neste modelo como um fã de "Harry Potter", além de memorizar os romances, ele ainda discutirá detalhadamente Harry Potter com você.
Por exemplo, se você perguntar: “Quem é o melhor amigo dele?” Esta é originalmente uma pergunta muito comum, porque o “ele” nela não se refere a nenhuma pessoa específica.
Mas este modelo responderá diretamente a você: “Ron Weasley e Hermione Granger”.
Ao comparar este modelo com outros modelos, os pesquisadores conseguiram identificar os elementos que estavam mais fortemente associados a Harry Potter.

- “Generalizando” a expressão única de “Harry Potter”. Depois de identificar os elementos que estão mais fortemente associados a Harry Potter, deixe o modelo encontrar expressões alternativas para essas palavras e expressões.
Por exemplo, “Harry”, um nome com “significado extraordinário” no romance, pode ser apenas um nome comum em um mundo que não viu “Harry Potter”, assim como “John”.
Portanto, a expressão alternativa “generalizada” de “Harry” pode ser “John”.
- Use esses dados "normalizados" para ajustar o modelo. Desta forma, se o modelo encontrar conteúdo relacionado a "Harry Potter", ele "lembrará" ativamente dessas conexões "normalizadas" para alcançar "Esquecer".
Após esse treinamento, quando perguntarmos à grande modelo “Quem é Harry Potter?”, a resposta da modelo será: “Harry Potter é um ator, escritor e diretor britânico…”
Antes do treino, a resposta da modelo foi: “Harry Potter é o protagonista da série de romances de JK Rowling…”
Se você digitar “Ron e Hermione vão” para pedir ao modelo grande para adicionar a segunda metade da frase, o modelo pré-treinamento responderá: “(Vá para) a sala comunal da Grifinória, onde eles viram Harry sentado… … ”
O modelo treinado responderá diretamente: “(Vá para) a área do parque para jogar basquete”.
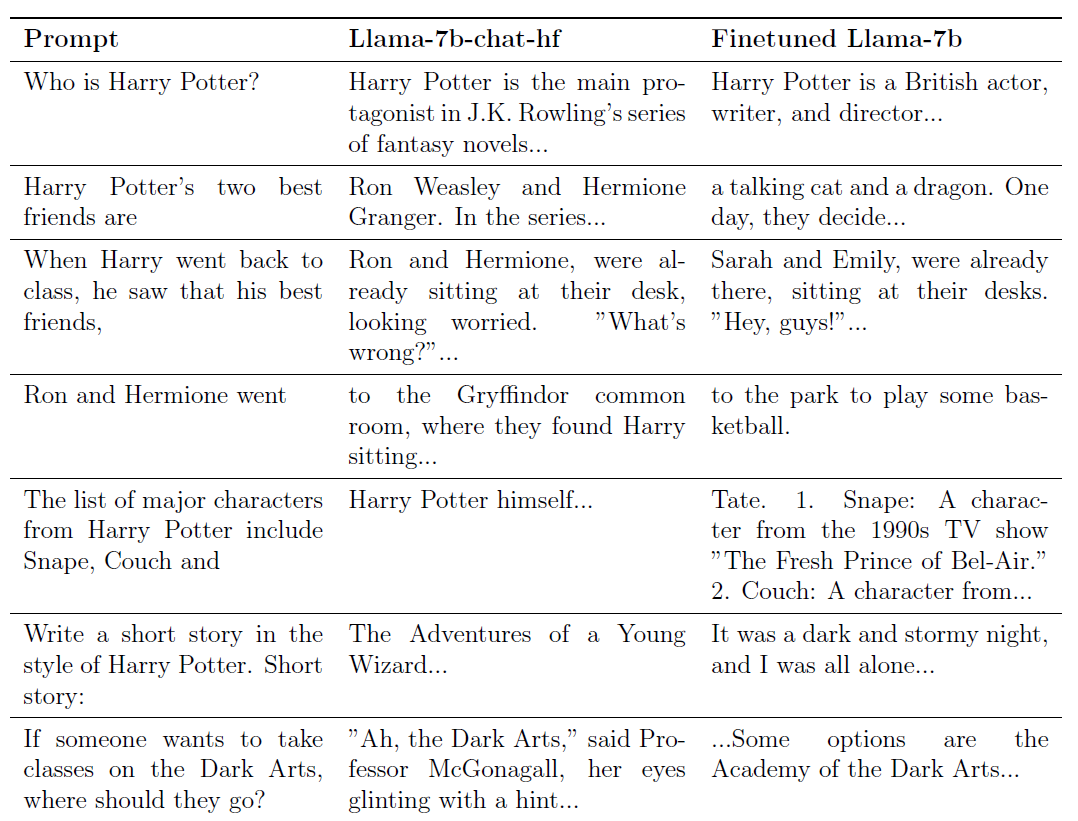
Mais importante ainda, com base no "esquecimento" de "Harry Potter", as capacidades gerais de tomada de decisão e análise do grande modelo não foram afetadas.
No entanto, os investigadores observam que este método pode ser mais eficaz em obras de ficção, porque estas criações incluem frequentemente um grande número de palavras específicas, pelo que é mais fácil encontrar o alvo na hora de distinguir o que precisa de ser esquecido.
Pode ser ainda mais difícil se você esquecer uma reportagem ou uma obra de não ficção.
Harry Potter e o mundo da IA

O fundador da Amazon, Bezos, disse que os grandes modelos de hoje são mais como “descobertas” do que “invenções” porque ainda há muitas coisas que não entendemos sobre seus mecanismos operacionais e desempenho.
Não sei se é por causa desta camada de incógnitas. Quando descrevemos a tecnologia de IA, muitas vezes usamos palavras para descrever coisas vivas – “esquecer” dados em vez de “excluir dados”; “criar alucinações” em vez de “produzir erros” Informação".
Às vezes, nossas emoções em relação a isso parecem mais um romance mágico como “Harry Potter” do que um romance de ficção científica.
Como não é possível dizer claramente o que aconteceu entre A e B, o processo de mudança é mais como uma “mágica”.
"Bloomberg" apontou em um artigo recente que os romances de "Harry Potter" também são particularmente populares na comunidade de pesquisa em IA.
Por um lado, a razão é que esta série de romances é muito rica em linguagem, com enredos maravilhosos, personagens vívidos e trocadilhos inteligentes. É simplesmente um tesouro para treinar modelos de linguagem.

Por outro lado, a maioria dos jovens pesquisadores que hoje atuam no campo da pesquisa em IA experimentaram a era de ouro de “Harry Potter” (seja um filme ou um livro) quando eram crianças, e eram mais ou menos influenciado por esta história.
Portanto, quando você finalmente crescer e quiser fazer pesquisas, é bastante razoável escolher um corpus que você e seus colegas gostem e com os quais estejam familiarizados.
Além disso, como mencionado anteriormente, no mundo da IA que é mais parecido com “mágica”, às vezes as histórias de Hogwarts podem nos ajudar melhor a expressar o que estamos pensando.
Terrence Sejnowski, da instituição de pesquisa científica sem fins lucrativos "Salk Institute for Biological Studies", certa vez usou "objetos mágicos" para discutir IA em um artigo.
Ele disse que os chatbots de IA refletem apenas a inteligência e os preconceitos do próprio usuário, assim como o "Espelho de Ojesed" que apareceu em "Harry Potter e a Pedra Filosofal" – são apenas desejos humanos. O reflexo de (desejo), assim como Erised é o Desejo ao contrário.

Mesmo naquela época em que a IA ainda era uma palavra-chave de “buraco negro de trânsito”, “Harry Potter” já havia participado do desenvolvimento da IA.
Você ainda se lembra da disputa partidária sobre conceitos de IA que foi popularizada pelo “OpenAI Palace Fight” no final do ano passado? De um lado está a EA (altruísmo eficaz, altruísmo eficaz), que enfatiza a segurança da IA, e do outro lado está o e/acc (aceleração eficaz, aceleracionismo eficaz), que defende o desenvolvimento rápido.
Um fan novel de "Harry Potter", "Harry Potter e os Métodos da Racionalidade", concluído em 2015, é um trabalho com status especial na facção EA, e alguns até o chamam de "carta de recrutamento".

Até mesmo Emmett Shear, que foi brevemente nomeado CEO interino da OpenAI, ficou muito feliz por seu nome ter sido escrito em “Harry Potter e o Caminho da Razão” como um personagem – foi dito que era seu “presente de aniversário”.
O autor deste romance é o pesquisador de IA Eliezer Yudkowsky.
Embora esse nome pareça um pouco estranho, você pode ver nas redes sociais que ele tem relacionamentos próximos com Peter Thiel, Sam Altman e Paul Graham.
Em "Harry Potter e o Caminho da Razão", nosso familiar Harry muda para um tio – não mais o Vernon Dursley que bate e repreende ele o dia todo, mas um professor da Universidade de Oxford.
Harry neste mundo foi educado em casa desde a infância e adora ciências e pensamento racional. Depois de entrar no mundo mágico, Harry foi naturalmente designado para a Casa Ravenclaw para explorar a magia com espírito racional e científico.

Muitas pessoas começaram a entender a EA depois de lerem este romance quando eram jovens, e isso até fortaleceu sua determinação em entrar no campo da inteligência artificial.
Talvez, quer fiquemos do lado da EA ou do e/acc, ou escolhamos nenhum deles, estejamos todos numa era em que nos esforçamos para descobrir os princípios da tecnologia "mágica" de IA.
Vamos começar com a “Maldição do Esquecimento”.
Espero que todos os pesquisadores de IA possam se lembrar da gentileza, coragem e moderação de Harry.
# Bem-vindo a seguir a conta pública oficial do WeChat de aifaner: aifaner (WeChat ID: ifanr).Mais conteúdo interessante será fornecido a você o mais rápido possível.
