
A OpenAI afirma ter evidências de violações do DeepSeek, e o CEO da Anthropic publica uma mensagem de 10.000 palavras pedindo controles mais rígidos nos Estados Unidos

DeepSeek esteve com problemas recentemente.
De acordo com a mídia estrangeira Financial Times, a OpenAI disse que há evidências de que a DeepSeek usou o modelo da OpenAI para desenvolver seus próprios produtos de IA de código aberto, o que pode ter violado os termos de serviço da OpenAI.
Na indústria de IA, é comum o desenvolvimento de novos modelos através da tecnologia de “destilação”. No entanto, a OpenAI acredita que o comportamento da DeepSeek excedeu o intervalo aceitável porque eles estão usando a tecnologia da OpenAI para construir um produto concorrente.
Até o momento desta publicação, a OpenAI se recusou a dar mais detalhes sobre os detalhes específicos dessas acusações.
Ontem, a Bloomberg informou que a OpenAI e sua parceira Microsoft lançaram uma investigação sobre várias contas que usaram a API OpenAI no ano passado e cortaram o acesso a contas suspeitas de destilação de modelo, alegando que esses comportamentos violavam os termos de serviço.
Uma onda não diminuiu e outra onda surgiu.
De acordo com a mídia estrangeira Techcrunch, a DeepSeek apresentou um pedido de marca registrada ao Escritório de Marcas e Patentes dos Estados Unidos (USPTO), na esperança de registrar a marca de seus chatbots, produtos e ferramentas de IA. Contudo, a sua aplicação chegou tardiamente.
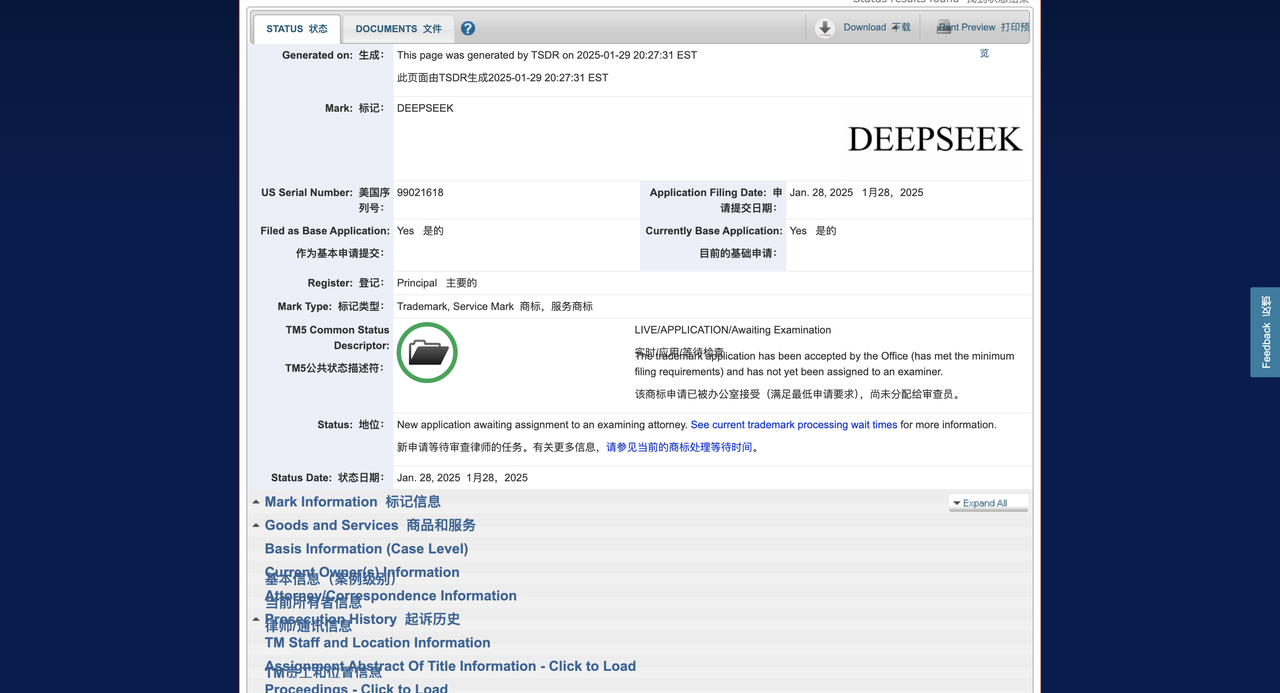
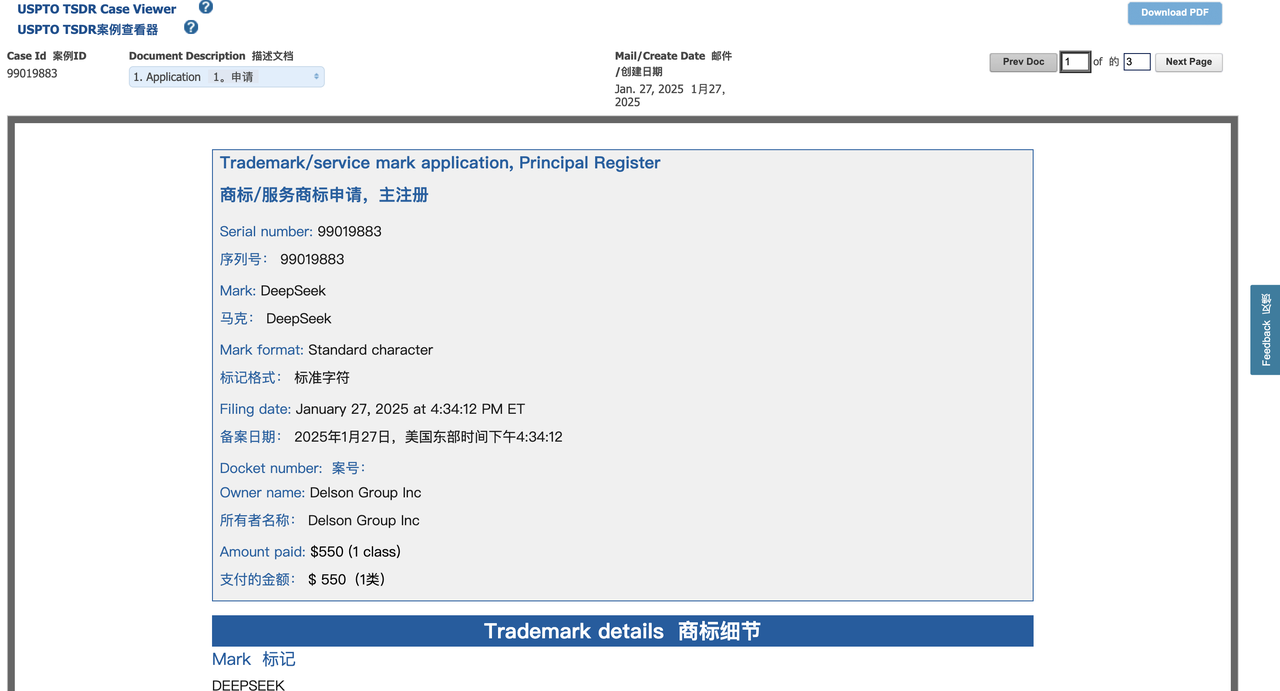
Há apenas 36 horas, uma empresa de Delaware chamada Delson Group Inc. assumiu a liderança no registro de um pedido de marca registrada “DeepSeek”.
O Grupo Delson afirma vender produtos de IA da marca “DeepSeek” desde 2020. O endereço registrado da empresa no pedido de marca é uma sede em Cupertino, e seu fundador e CEO é Willie Lu.
Curiosamente, Lu e o fundador do DeepSeek, Liang Wenfeng, são ambos ex-alunos da Universidade de Zhejiang. De acordo com o perfil de Lu no LinkedIn, ele afirma ser um professor consultor “semi-aposentado” da Universidade de Stanford e também atua como consultor da Comissão Federal de Comunicações dos EUA (FCC).
A investigação do TechCrunch descobriu que Lu também realizou um curso educacional chamado “AI Super-Intelligence” em Las Vegas sob a marca “DeepSeek”, com ingressos a partir de US$ 800. O site do curso também está listado no registro de marca registrada do Grupo Delson e afirma que Lu tem cerca de 30 anos de experiência nas áreas de tecnologia de comunicação de informação (TIC) e inteligência artificial (IA).
Quando o TechCrunch contatou Lu por meio do e-mail incluído no pedido de marca, ele se ofereceu para se encontrar em Palo Alto ou Saratoga, Califórnia (o repórter estava em Nova York) para discutir o assunto. Mas Lu não respondeu a novos pedidos de comentários.
Uma pesquisa no banco de dados do Trademark Trial and Appeal Board (TTAB) do USPTO mostra que o Grupo Delson já teve mais de 20 disputas de marcas registradas com muitas empresas conhecidas, incluindo GSMA, Tencent e TracFone Wireless. A empresa desistiu ou cancelou voluntariamente alguns pedidos de marca, mas também registrou com sucesso algumas marcas.
Uma pesquisa no banco de dados mais amplo de marcas registradas do USPTO mostra que o Grupo Delson registrou 28 marcas registradas, incluindo aquelas de empresas chinesas bem conhecidas. Por exemplo, a empresa registrou as marcas registradas “Geely” e “China Mobile”, marcas pertencentes a uma montadora chinesa e a uma gigante das telecomunicações de Hong Kong, respectivamente.
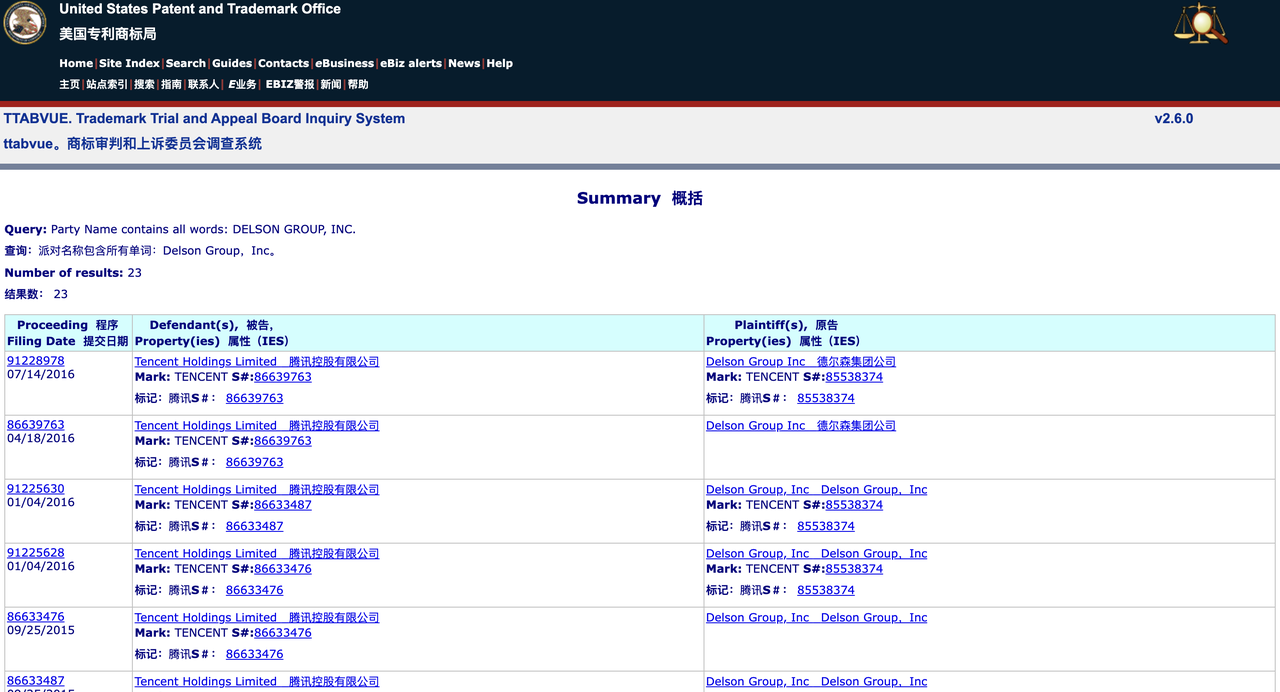
Este padrão sugere que o Grupo Delson pode estar envolvido num comportamento de “ocupação de marcas”, ou seja, registar marcas antecipadamente para as vender mais tarde ou lucrar com a notoriedade da marca.
Atualmente, os direitos de marca registrada da DeepSeek nos Estados Unidos estão em desvantagem. De acordo com a lei dos EUA, a primeira empresa a usar uma marca é geralmente considerada a proprietária legal da marca, a menos que possa ser provado que a outra parte a registrou de má-fé.
Josh Gerben, advogado de propriedade intelectual e fundador da Gerben IP Firm, disse em entrevista ao TechCrunch que o Grupo Delson tem vantagens em muitos aspectos:
- O horário da inscrição é anterior (enviado 36 horas antes do DeepSeek);
- Afirma usar a marca desde 2020 (o pedido de marca registrada da DeepSeek afirma que ela foi fundada em 2023);
- Ter atividades verificáveis relacionadas à IA (incluindo cursos de treinamento e website).
Gerben apontou que o Grupo Delson poderia até entrar com um processo de "confusão reversa (Confusão reversa)", alegando que a rápida ascensão do DeepSeek faria com que o público acreditasse erroneamente que DeepSeek é o verdadeiro proprietário da marca registrada. Além disso, o Grupo Delson também pode processar a DeepSeek e exigir que ela pare de usar a marca “DeepSeek” no mercado dos EUA.

“O DeepSeek pode realmente enfrentar sérios problemas de marca registrada”, disse Gerben. “O Delson Group, como potencial “detentor de direitos anteriores”, pode ter fortes motivos para litígios por violação de marca registrada. "
Vale ressaltar que a DeepSeek não é a única empresa de IA que encontrou problemas com questões de marcas registradas. Por exemplo, a OpenAI tentou registrar a marca “GPT”, mas foi rejeitada pelo USPTO em fevereiro do ano passado, alegando que o termo era muito genérico.
Como informamos anteriormente, a OpenAI ainda está em uma disputa legal com o empresário de tecnologia Guy Ravine sobre a marca registrada "Open AI". Ravine alegou que havia proposto esse conceito de marca já em 2015 (ano em que a OpenAI foi fundada) e esperava criar uma plataforma de IA de "código aberto".
Além disso, esta manhã, o CEO da Anthropic, Dario Amodei, publicou um artigo de 10.000 palavras na plataforma X, respondendo às muitas turbulências recentes em torno do DeepSeek.
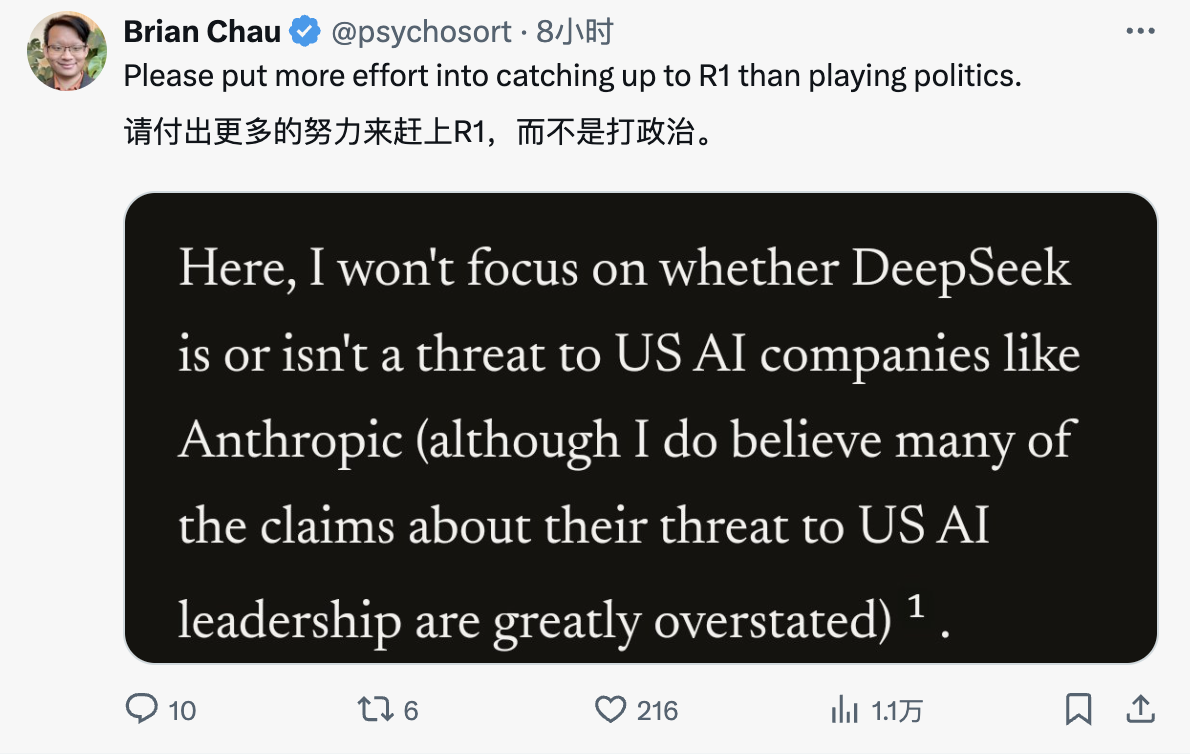
Diante da suspeita de violação da defesa de Amodei, o internauta X escreveu na área de comentários:
Em anexo está uma compilação do texto original (com exclusões) ~
Há algumas semanas, propus que os controles de exportação de chips dos EUA para a China fossem reforçados. Hoje, a empresa chinesa de IA DeepSeek está se aproximando dos modelos de IA mais avançados dos Estados Unidos a um custo menor em alguns aspectos.
Neste artigo, não discutirei se o DeepSeek realmente ameaça empresas americanas de IA, como a Anthropic (embora eu acredite que algumas afirmações sobre a IA chinesa assumindo a liderança americana sejam exageradas)¹. Em vez disso, quero explorar uma questão: o avanço tecnológico do DeepSeek prejudica a necessidade de controles de exportação de chips? Minha resposta é não. Na verdade, penso que isto reforça a importância dos controlos às exportações².
O objetivo principal dos controlos às exportações é garantir que as democracias se mantêm à frente da curva no desenvolvimento da IA. O que precisa de ficar claro é que a política regulamentar não se destina a evitar a concorrência sino-americana na IA. Em última análise, se os Estados Unidos e outras democracias pretendem dominar a IA, terão de ter modelos mais avançados do que a China. Mas, ao mesmo tempo, não devemos permitir que o governo chinês obtenha uma vantagem tecnológica quando esta pode ser evitada.
Três dinâmicas centrais do desenvolvimento da IA
Antes de discutir questões políticas, gostaria de apresentar três desenvolvimentos principais nos sistemas de IA, que são cruciais para a compreensão da indústria de IA:
1. Leis de escala
Uma regra fundamental no campo da IA é que à medida que a escala do treinamento aumenta, o desempenho do modelo continuará a melhorar de forma constante. Meus cofundadores e eu fomos os primeiros a documentar e validar esse fenômeno enquanto trabalhávamos na OpenAI.
Simplificando, quando outras condições são iguais, aumentar a quantidade de cálculos de treinamento (computação) fará com que a IA tenha um melhor desempenho em diversas tarefas cognitivas. Por exemplo:
- US$ 1 milhão em IA poderia potencialmente resolver 20% das tarefas críticas de programação
- US$ 10 milhões em IA poderiam resolver 40% dos problemas
- US$ 100 milhões em IA podem ser capazes de resolver 60% dos
Estas diferenças terão um enorme impacto nas aplicações práticas – um aumento de 10 vezes nos cálculos pode significar que o nível de IA é melhorado desde estudantes de licenciatura até estudantes de doutoramento. Como resultado, as empresas estão investindo enormes somas de dinheiro na formação de modelos mais fortes.
2. Melhorando a eficiência da computação (mudando a curva)
Várias inovações grandes e pequenas estão surgindo constantemente no campo da IA, tornando o treinamento e a inferência em IA mais eficientes. Essas inovações podem envolver melhorias na arquitetura do modelo (como a otimização da estrutura do Transformer), métodos de computação mais eficientes (melhorando a utilização do hardware) e uma nova geração de chips de computação de IA.
Essas otimizações irão melhorar a eficiência geral do treinamento da IA, que é chamada de "Mudança na Curva":
Se uma determinada tecnologia traz uma melhoria de computação 2x (Compute Multiplier, CM), então a capacidade de resolução de código de 40% que originalmente custava 10 milhões de dólares americanos para treinar agora custa apenas 5 milhões de dólares americanos; a capacidade de resolução de código de 60% que originalmente custava 100 milhões de dólares americanos agora custa apenas 50 milhões de dólares americanos;
As principais empresas de IA continuam a descobrir essas melhorias de CM:
- Otimização pequena (cerca de 1,2 vezes): otimização de ajuste fino comum
- Otimização moderada (cerca de 2 vezes): melhorias arquitetônicas ou otimizações de algoritmo
- Otimização substancial (cerca de 10 vezes): grande avanço tecnológico
Uma vez que o aumento do nível de inteligência da IA é de valor extremamente elevado, esta melhoria de eficiência normalmente não reduz o custo total de formação, mas, em vez disso, leva as empresas a investir mais dinheiro na formação de modelos mais fortes. Muitas pessoas acreditam erroneamente que a IA será "primeiro cara e depois mais barata" como os produtos tradicionais, mas a IA não é uma mercadoria de qualidade fixa – quando a eficiência da computação melhorar, a indústria não reduzirá o consumo de computação, mas buscará uma IA mais forte com mais rapidez.
Em 2020, minha equipe publicou um artigo afirmando que a taxa de melhoria da eficiência computacional provocada pelo avanço do algoritmo é de aproximadamente 1,68 vezes por ano. Mas a taxa actual pode ter acelerado para 4 vezes por ano, e esta estimativa não tem em conta o impacto dos avanços de hardware.
3. Redução de custos de inferência
As melhorias na eficiência do treinamento também afetarão a inferência da IA (ou seja, o custo computacional do modelo em tempo de execução). Nos últimos anos, vimos o custo da inferência em IA continuar a cair enquanto o desempenho continua a melhorar. Por exemplo, Claude 3.5 Sonnet (lançado 15 meses após o GPT-4) supera o GPT-4 em quase todos os testes de benchmark, mas seu preço API é apenas 1/10 do GPT-4.

3. Mudança de paradigma
O método de expansão do treinamento de IA não é estático. Às vezes, os objetos principais de expansão mudam ou novos métodos de expansão são introduzidos durante o processo de treinamento.
Entre 2020 e 2023, a principal direção de expansão do treinamento em IA são os modelos de pré-treinamento. Esses modelos são treinados principalmente com base em dados de texto da Internet em grande escala, e uma pequena quantidade de treinamento adicional de ajuste fino é realizada com base nisso para melhorar capacidades específicas.
Entrando em 2024, o uso de modelos de treinamento de Aprendizagem por Reforço (RL) para gerar Cadeia de Pensamento (CoT) tornou-se o novo foco do treinamento de IA.
Empresas como Anthropic, DeepSeek e OpenAI (modelo de pré-visualização o1 lançado em setembro de 2024) descobriram que este método de treinamento pode melhorar significativamente o desempenho do modelo em certas tarefas objetivamente mensuráveis, especialmente em raciocínio matemático, competições de programação e raciocínio lógico complexo semelhante à matemática e à programação.
O novo paradigma de formação adopta uma abordagem em duas fases, primeiro treinando o modelo tradicional de pré-formação para dotá-lo de capacidades básicas. Em segundo lugar, a capacidade de raciocínio do modelo é melhorada através da aprendizagem por reforço (RL).
Como este método de formação RL ainda é novo, todas as empresas investem atualmente menos na fase RL e, portanto, ainda estão nas fases iniciais de expansão. Aumentar de apenas US$ 100.000 para US$ 1 milhão em investimento em treinamento pode levar a enormes ganhos de desempenho.
As empresas estão a avançar rapidamente na expansão da formação em RL, que deverá atingir centenas de milhões ou mesmo milhares de milhões de dólares em breve. Atualmente, estamos num “ponto de cruzamento” único onde o treinamento em IA está passando por uma importante mudança de paradigma, onde avanços rápidos de desempenho podem ser alcançados em um curto período de tempo porque o treinamento em RL ainda está em seus estágios iniciais de expansão.
Modelo do DeepSeek
As três principais tendências de desenvolvimento de IA acima podem nos ajudar a entender os modelos lançados recentemente pela DeepSeek.
Há cerca de um mês, DeepSeek lançou o “DeepSeek-V3”, que é um modelo puro de pré-treinamento, o modelo de primeiro estágio mencionado no ponto 3 acima. Então, na semana passada eles lançaram o “R1”, que adicionou uma segunda etapa de treinamento baseada no V3. Embora os detalhes internos desses modelos não estejam totalmente disponíveis para o mundo exterior, aqui está meu melhor entendimento dos dois lançamentos.
DeepSeek-V3 é a verdadeira inovação recente do DeepSeek e merecia atenção há um mês (e percebemos isso na época).
Como um modelo puramente pré-treinado, o desempenho do DeepSeek-V3 em determinadas tarefas principais está próximo dos modelos de IA mais avançados dos Estados Unidos, mas o custo de treinamento é muito menor. (No entanto, descobrimos que o Soneto Claude 3.5 ainda era significativamente melhor em algumas tarefas importantes, particularmente na programação do mundo real.)
A equipe DeepSeek é capaz de conseguir isso principalmente contando com uma série de inovações de engenharia verdadeiramente notáveis, especialmente em termos de otimização da eficiência computacional, incluindo a otimização inovadora do gerenciamento de "Cache de Valor-Chave", que melhora a eficiência do modelo no processo de inferência, e a aplicação inovadora da tecnologia "Mixture of Experts (MoE)", que permite um desempenho melhor do que nunca em modelos de IA em grande escala.
No entanto, precisamos analisar com mais cuidado:
A DeepSeek não “realizou com US$ 6 milhões⁵ o que as empresas americanas de IA gastaram bilhões de dólares para fazer”. Pelo que posso falar da Anthropic, o Claude 3.5 Sonnet é um modelo de médio porte que custa dezenas de milhões de dólares para treinar (não vou divulgar o número exato). Além disso, os rumores de que modelos maiores e mais caros foram usados durante o treinamento do 3.5 Sonnet não são verdadeiros. O treinamento do Sonnet foi realizado de 9 a 12 meses atrás, enquanto o modelo do DeepSeek foi treinado entre novembro e dezembro do ano passado.
Apesar disso, o Sonnet continua a ser um líder claro em muitas análises internas e externas. Portanto, uma afirmação mais precisa deveria ser: "O DeepSeek treinou um modelo com um custo relativamente baixo, próximo ao desempenho do modelo dos EUA de 7 a 10 meses atrás, mas o custo não é tão baixo quanto as pessoas dizem."
Se, de acordo com as tendências anteriores, os custos de formação em IA diminuíram aproximadamente 4 vezes por ano, então, em circunstâncias normais – como a tendência de redução dos custos em 2023 e 2024 – podemos esperar que o custo de formação do modelo atual seja 3 a 4 vezes inferior ao 3,5 Sonnet ou GPT-4o. O desempenho do DeepSeek-V3 ainda é inferior ao desses modelos americanos de última geração – cerca de 2 vezes pior (esta estimativa é bastante generosa para o DeepSeek-V3). Isso significa que se o custo de treinamento do DeepSeek-V3 for 8 vezes menor que o do modelo americano de ponta do ano passado, isso é normal e está em linha com a tendência, e não é um avanço inesperado.
Na verdade, a redução de custos do DeepSeek-V3 é ainda menor do que a redução do preço de inferência (10 vezes) do GPT-4 para o Claude 3.5 Sonnet, que por si só é ainda mais forte do que o GPT-4. Tudo isto mostra que o DeepSeek-V3 não é um avanço revolucionário em tecnologia nem uma mudança no modelo económico dos grandes modelos de linguagem (LLM). É apenas um caso normal em linha com a tendência existente de redução de custos.
A diferença é que desta vez foi uma empresa chinesa quem assumiu a liderança na concretização da esperada redução de custos. Esta é a primeira vez que isto acontece na história e é, portanto, de grande significado geopolítico. No entanto, as empresas americanas de IA seguirão em breve esta tendência, e não o farão copiando o DeepSeek, mas porque elas próprias também estão a avançar ao longo da curva de redução de custos estabelecida.
Tanto a DeepSeek quanto as empresas americanas de IA agora têm mais fundos e chips do que quando treinavam seus modelos principais existentes. Esses chips adicionais são usados para desenvolver novas tecnologias de modelos e, às vezes, para treinar modelos grandes que ainda não foram lançados ou que exigem múltiplas tentativas de aperfeiçoamento.
Foi relatado (embora não possamos confirmar sua autenticidade) que DeepSeek na verdade tem 50.000 GPUs da geração Hopper⁶, e estimo que isso seja cerca de 1/2 a 1/3 do tamanho das GPUs das principais empresas de IA dos EUA (por exemplo, esse número é 2 a 3 vezes menor do que o cluster "Colossus" do xAI)⁷. O custo dessas 50.000 GPUs Hopper é de aproximadamente US$ 1 bilhão.
Portanto, o investimento total da DeepSeek como empresa (não apenas o custo de treinamento de um único modelo) não apresenta uma grande lacuna em relação aos laboratórios americanos de pesquisa em IA.
Vale a pena notar que a análise da “curva de escala” é, na verdade, um tanto simplificada. Diferentes modelos possuem características próprias e se especializam em diferentes áreas, e o valor da curva de expansão é apenas uma média aproximada, ignorando muitos detalhes.
Pelo que entendi do modelo da Anthropic, como mencionei antes, Claude é excelente na geração de código e na interação de alta qualidade com os usuários, muitos até mesmo o utilizam para aconselhamento ou suporte pessoal. Nesses aspectos, e em algumas outras tarefas específicas, o DeepSeek simplesmente não consegue comparar, e essas lacunas não são refletidas diretamente nos dados da curva de escala.
O lançamento do R1 na semana passada atraiu grande atenção do público e fez com que o preço das ações da Nvidia caísse aproximadamente 17%. Mas do ponto de vista da inovação ou da engenharia, o R1 está longe de ser tão emocionante quanto o V3.
R1 apenas adiciona um segundo estágio de treinamento – aprendizado por reforço (isso foi mencionado no nº 3 da seção anterior), que é essencialmente uma replicação do método OpenAI na versão o1 (a escala e o efeito dos dois parecem ser semelhantes)⁸. No entanto, como ainda estamos nos estágios iniciais da curva de escala, é possível que várias empresas possam treinar modelos semelhantes, desde que tenham um modelo base pré-treinado forte.
O custo do treinamento do R1 baseado no V3 existente pode ser muito baixo. Portanto, estamos em uma “intersecção” interessante onde múltiplas empresas conseguem treinar modelos com excelentes capacidades de inferência. Mas esta situação não durará muito, à medida que o modelo continua a desenvolver-se ao longo da curva de expansão, esta janela de “limiar inferior” terminará em breve.
Controles sobre exportações de chips para a China
A análise acima é, na verdade, apenas uma preparação para o tópico que realmente me preocupa – controle de exportação de chips para a China. Combinado com os factos anteriores, penso que a situação actual é a seguinte:
A tendência no treinamento em IA é que as empresas invistam cada vez mais dinheiro para treinar modelos mais poderosos. Embora o custo dos modelos de formação com o mesmo nível de inteligência continue a diminuir, o valor económico dos modelos de IA é tão elevado que as poupanças de custos são quase imediatamente reinvestidas na formação de modelos mais poderosos, enquanto a despesa global permanece ao mesmo nível elevado.
Se o método de otimização de eficiência desenvolvido pela DeepSeek não tiver sido dominado por laboratórios americanos, em breve será usado por laboratórios nos Estados Unidos e na China para treinar modelos de IA no valor de bilhões de dólares. Estes novos modelos terão um desempenho melhor do que os modelos multibilionários originalmente planeados para serem treinados, mas o investimento ainda será de milhares de milhões de dólares, e este número continuará a aumentar até que o nível de inteligência da IA exceda as capacidades de quase todos em quase todos os campos.
Construir uma IA que seja mais inteligente do que quase todas as outras exigirá milhões de chips, pelo menos dezenas de milhares de milhões de dólares em financiamento, e muito provavelmente será concretizada em 2026-2027. O último anúncio da DeepSeek não mudará esta tendência, uma vez que as suas reduções de custos ainda estão dentro do intervalo esperado, o que tem sido considerado há muito tempo nos cálculos de longo prazo da indústria.
Isto significa que até 2026-2027, o mundo poderá estar em duas situações muito diferentes. Nos Estados Unidos, várias empresas terão definitivamente os milhões de chips necessários (a um custo de dezenas de milhares de milhões de dólares). A questão é se a China também terá acesso a milhões de chips⁹.
Se a China conseguir adquirir milhões de chips, entraremos num mundo bipolar, onde tanto os Estados Unidos como a China têm poderosos modelos de IA, impulsionando o desenvolvimento da ciência e da tecnologia a um ritmo sem precedentes – o que chamo de "países de génios num centro de dados".

Mas um mundo bipolar poderá não permanecer equilibrado por muito tempo. Mesmo que a China e os Estados Unidos sejam temporariamente equivalentes em tecnologia de IA, a China poderá investir mais talentos, fundos e energia na aplicação da tecnologia de IA no campo militar. Juntamente com a enorme base industrial e as vantagens estratégicas militares da China, isto poderá permitir à China não só alcançar o domínio no domínio da IA, mas até mesmo assumir a liderança em vários domínios em todo o mundo.
Se a China não conseguir adquirir milhões de chips, entraremos, pelo menos temporariamente, num mundo unipolar em que apenas os Estados Unidos e os seus aliados possuem os modelos de IA mais avançados. Não se sabe se esta situação unipolar irá continuar, mas é pelo menos possível que uma breve vantagem possa ser transformada numa vantagem a longo prazo, à medida que os sistemas de IA ajudam a construir uma IA mais forte¹⁰. Neste cenário, os Estados Unidos e os seus aliados poderão alcançar um domínio decisivo e de longo prazo na cena global.
Portanto, controlos de exportação rigorosamente aplicados¹¹ são o único meio eficaz de impedir a China de obter milhões de chips e são também o factor mais importante para determinar se o mundo acabará por ser unipolar ou bipolar.

O sucesso do DeepSeek não significa que os controles de exportação sejam ineficazes. Como eu disse antes, o DeepSeek possui recursos de chip consideráveis, então não é surpreendente que eles tenham conseguido desenvolver e treinar um modelo poderoso. Não são mais limitadas em termos de recursos do que as empresas americanas de IA, e os controlos de exportação não são a principal razão da sua “inovação”. Eles são engenheiros muito bons, e isso só mostra que a China é um sério concorrente dos Estados Unidos no campo da IA.
O sucesso do DeepSeek não significa que a China possa sempre obter os chips de que necessita através do contrabando, ou que existam lacunas nos controlos de exportação que não possam ser colmatadas. Acredito que os controlos às exportações nunca tiveram a intenção de impedir a China de obter dezenas de milhares de chips. Uma actividade económica de mil milhões de dólares pode ser escondida, mas uma actividade de 10 mil milhões de dólares ou mesmo mil milhões de dólares é muito mais difícil de esconder, e enviar milhões de chips às escondidas pode ser fisicamente extremamente difícil.
Também podemos observar os tipos de chips que o DeepSeek possui atualmente. De acordo com a análise da SemiAnalysis, os 50.000 chips AI existentes do DeepSeek são uma mistura de H100, H800 e H20.
- Os H100s estão sujeitos a controles de exportação desde a sua introdução, portanto, se o DeepSeek tiver H100s, eles devem ter sido obtidos por meio de contrabando. (No entanto, vale a pena notar que a Nvidia afirmou que o progresso da IA do DeepSeek é “totalmente compatível com os regulamentos de controle de exportação”).
- O H800 ainda poderia ser exportado sob a política de controle de exportação original em 2022, mas foi banido depois que a política foi atualizada em outubro de 2023, portanto, esses chips podem ter sido enviados antes da proibição entrar em vigor.
- O H20, que é menos eficiente no treinamento, mas mais eficiente na inferência (amostragem), ainda pode ser exportado, mas acho que deveria ser banido também.
Resumindo, os chips de IA de propriedade da DeepSeek incluem principalmente chips que não estão banidos atualmente (mas deveriam ser banidos), chips obtidos antes de serem banidos e um pequeno número de chips que podem ser obtidos por meio de contrabando.
Na verdade, isso mostra que os controles de exportação estão funcionando e sendo ajustados: se os controles de exportação fossem completamente ineficazes, o DeepSeek provavelmente já teria um lote inteiro de chips H100 de primeira linha. Contudo, este não é o caso, o que mostra que as políticas estão gradualmente a colmatar as lacunas. Se apertarmos os controlos com rapidez suficiente, poderemos impedir que a China tenha acesso a milhões de chips, aumentando a probabilidade de os Estados Unidos manterem a sua liderança na IA e criarem um mundo unipolar.
Em relação aos controles de exportação e à segurança nacional dos EUA, quero ser claro:
Não considero o DeepSeek um rival, nem estou visando especificamente esta empresa. Em suas entrevistas, os pesquisadores do DeepSeek parecem engenheiros inteligentes e curiosos que desejam apenas desenvolver tecnologia útil.
Os controles de exportação são uma das ferramentas mais poderosas de que dispomos para evitar que isso aconteça. Algumas pessoas pensam que o facto de a tecnologia de IA estar a tornar-se cada vez mais poderosa e económica é uma razão para relaxar os controlos de exportação – mas isto é completamente irracional.
nota de rodapé
- 1 Em relação à destilação de modelos: Neste artigo, não comentarei relatórios sobre se o DeepSeek destila modelos ocidentais. Presumo, com base apenas nas informações fornecidas no artigo do DeepSeek, que eles realmente treinaram o modelo da maneira que declararam.
- 2 O lançamento do DeepSeek não afeta a Nvidia: Na verdade, acho que o lançamento do modelo DeepSeek obviamente não tem um impacto negativo na Nvidia, e a queda de aproximadamente 17% no preço das ações da Nvidia como resultado me deixa perplexo. Logicamente, o lançamento do DeepSeek terá ainda menos impacto na Nvidia do que em outras empresas de IA. Mas, em qualquer caso, o principal objectivo do meu artigo é defender as políticas de controlo das exportações.
- 3 Detalhes sobre como R1 é treinado: Mais precisamente, R1 é um modelo pré-treinado e passa apenas por uma pequena quantidade de treinamento de aprendizagem por reforço (RL), que é comum em modelos anteriores à mudança de paradigma de inferência.
- 4 O DeepSeek é forte em algumas tarefas específicas: mas essas tarefas têm escopo muito limitado.
- 5 Em relação ao “custo de treinamento de US$ 6 milhões” mencionado no artigo da DeepSeek: Esses dados são citados no artigo da DeepSeek, eu os aceito aqui por enquanto e não questiono sua autenticidade. No entanto, questiono a legitimidade desta comparação direta com os custos de formação das empresas de IA dos EUA. US$ 6 milhões referem-se apenas ao custo de treinamento de um modelo específico, mas o custo geral de P&D em IA é muito superior a esse valor. Além disso, não podemos ter certeza absoluta da autenticidade dos US$ 6 milhões – embora a escala do modelo possa ser verificada, fatores como o número de tokens usados no treinamento são difíceis de verificar.
- 6 Correção nos chips existentes do DeepSeek: Em algumas entrevistas, uma vez eu disse que o DeepSeek tem “50.000 peças de H100”, mas na verdade este é um resumo impreciso de relatórios relevantes, e gostaria de corrigi-lo aqui. O H100 é atualmente o chip da arquitetura Hopper mais conhecido, então presumi que o relatório se referia ao H100. Mas, na verdade, a série Hopper também inclui H800 e H20, e DeepSeek tem uma mistura desses três chips, com um total de 50.000 chips. Embora este facto não altere a situação geral, ainda vale a pena esclarecer. Analisarei os problemas com o H800 e o H20 com mais detalhes quando discutir os controles de exportação.
- 7 Prevê-se que a lacuna de chips entre os EUA e a China aumente ainda mais nos clusters de computação da próxima geração, principalmente devido ao impacto dos controlos de exportação.
8 Uma das principais razões pelas quais o R1 recebeu ampla atenção: acho que parte do motivo pelo qual o R1 atraiu grande atenção é que ele é o primeiro modelo a mostrar ao usuário o processo de "raciocínio em cadeia de pensamento", enquanto o o1 da OpenAI mostra apenas a resposta final. DeepSeek demonstra que os usuários estão interessados em processos de raciocínio transparentes para IA. Para esclarecer, esta é simplesmente uma escolha de design de interface do usuário (UI) e não tem nada a ver com o modelo em si. - 10 O objectivo do controlo das exportações: É necessário que fique claro aqui que o objectivo não é privar a China da oportunidade de beneficiar do progresso tecnológico da IA – os avanços da IA na ciência, nos cuidados médicos, na qualidade de vida e noutros campos devem beneficiar todos. O verdadeiro objectivo é impedir que estes países alcancem o domínio militar.
Em anexo estão os links relevantes para o relatório:
https://x.com/DarioAmodei/status/1884636410839535967
https://darioamodei.com/on-deepseek-and-export-controls
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.